
大纲
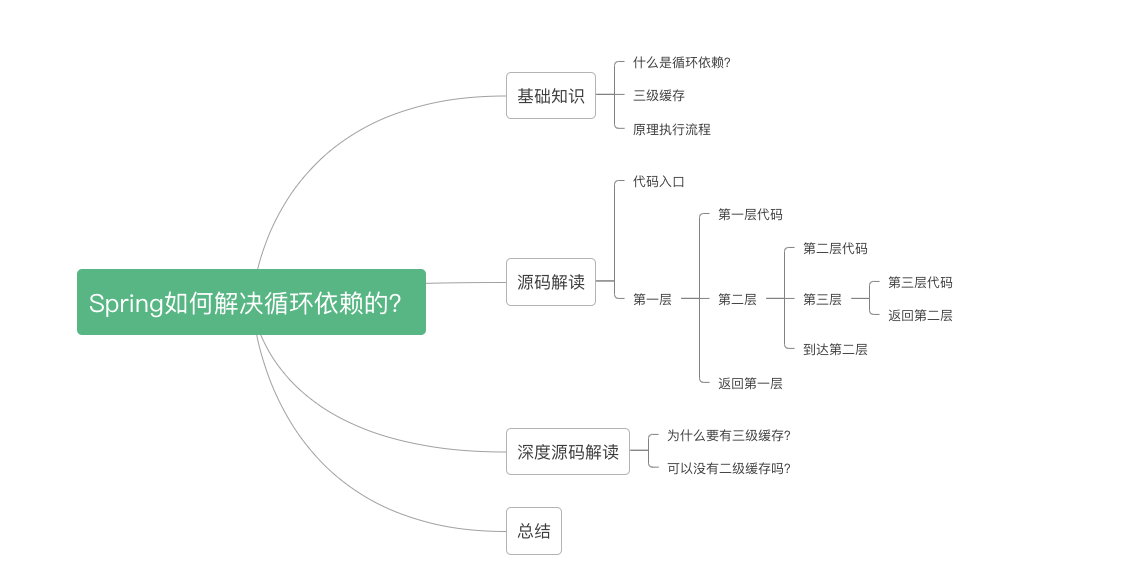
基础知识
1.1什么是循环依赖?
一个或多个对象之间存在直接或间接的依赖关系,这种依赖关系构成一个环形调用,有下面 3 种方式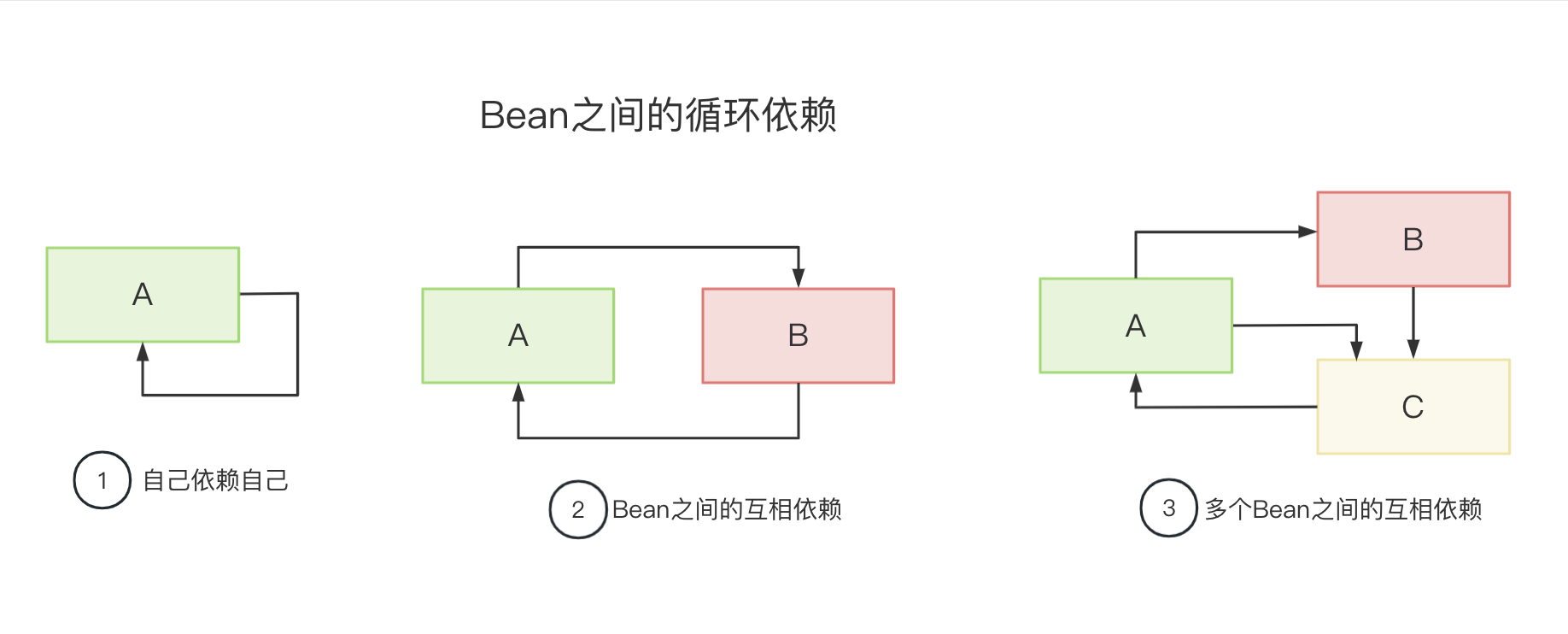
我们看一个简单的 Demo,对标“情况 2”。
1 |
|
这是一个经典的循环依赖,它能正常运行,后面我们会通过源码的角度,解读整体的执行流程。
1.2 三级缓存概念
spring就是通过三级缓存去解决的循环依赖的问题。
- 第一级缓存:singletonObjects,用于保存实例化、注入、初始化完成的Bean实例
- 第二级缓存:earlySingletonObjects,用于保存实例化完成的Bean
- 第三级缓存:singletonFactories,用于保存Bean创建工厂,以便后面有机会创建对象
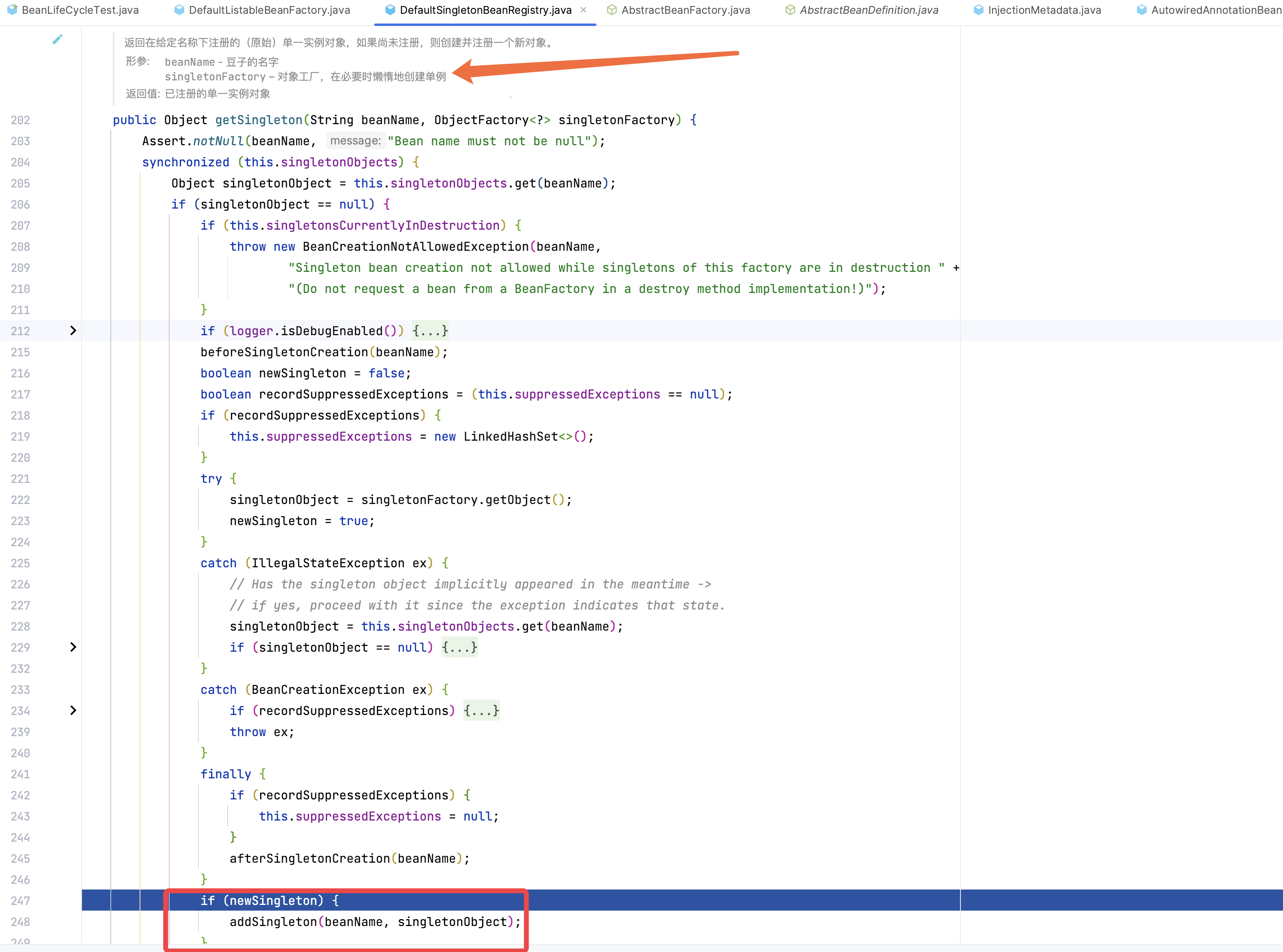
我们查看下具体的获取单例源码:
执行逻辑:
1.3 原理执行流程
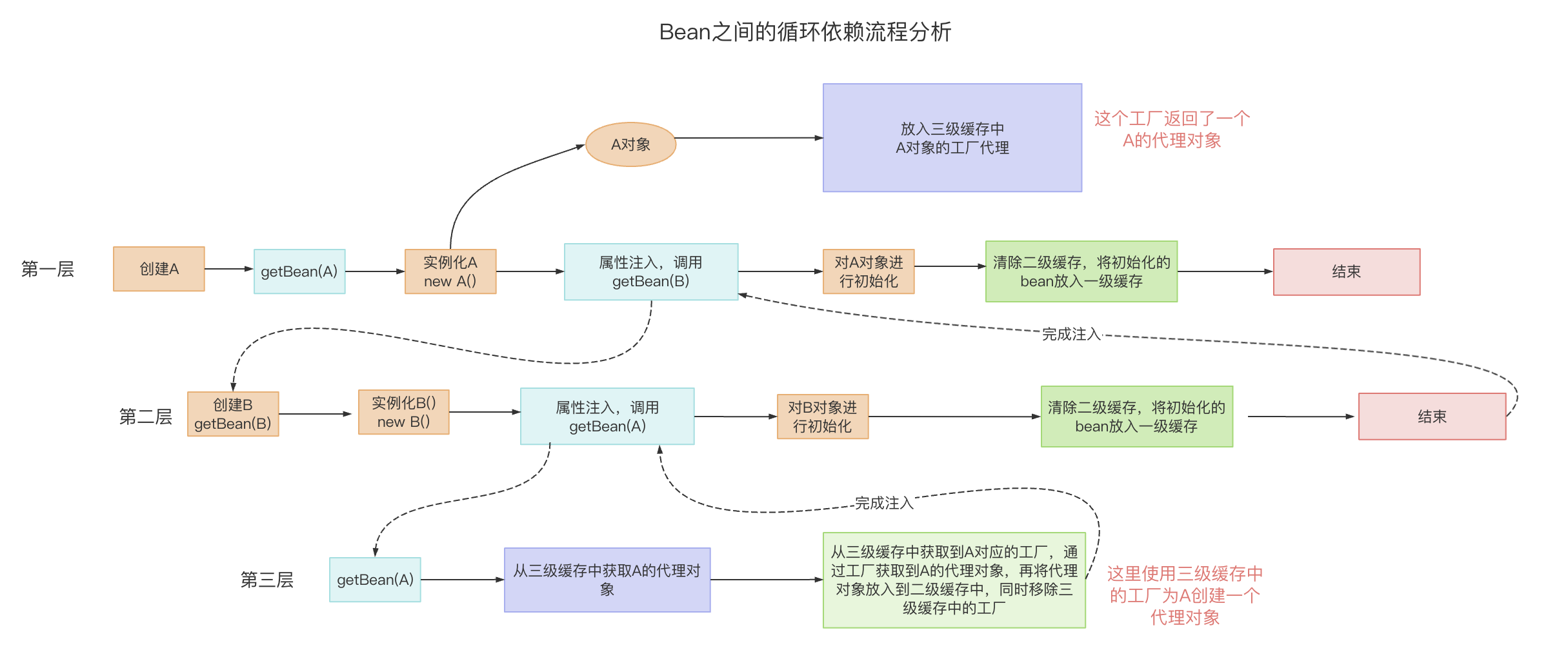
- 在第一层中,先去获取 A 的 Bean,发现没有就准备去创建一个,然后将 A 的代理工厂放入“三级缓存”(这个 A 其实是一个半成品,还没有对里面的属性进行注入),但是 A 依赖 B 的创建,就必须先去创建 B;
- 在第二层中,准备创建 B,发现 B 又依赖 A,需要先去创建 A;
- 在第三层中,去创建 A,因为第一层已经创建了 A 的代理工厂,直接从“三级缓存”中拿到 A 的代理工厂,获取 A 的代理对象,放入“二级缓存”,并清除“三级缓存”;
- 回到第二层,现在有了 A 的代理对象,对 A 的依赖完美解决(这里的 A 仍然是个半成品),B 初始化成功;
- 回到第一层,现在 B 初始化成功,完成 A 对象的属性注入,然后再填充 A 的其它属性,以及 A 的其它步骤(包括 AOP),完成对 A 完整的初始化功能(这里的 A 才是完整的 Bean)。
- 将 A 放入“一级缓存”。
源码分析
我们以AService、BService之间的依赖关系,来调试这一段代码。
找到代码入口
在Spring的AbstractApplicationContext#refresh函数中,重点查看 finishBeanFactoryInitialization(beanFactory)函数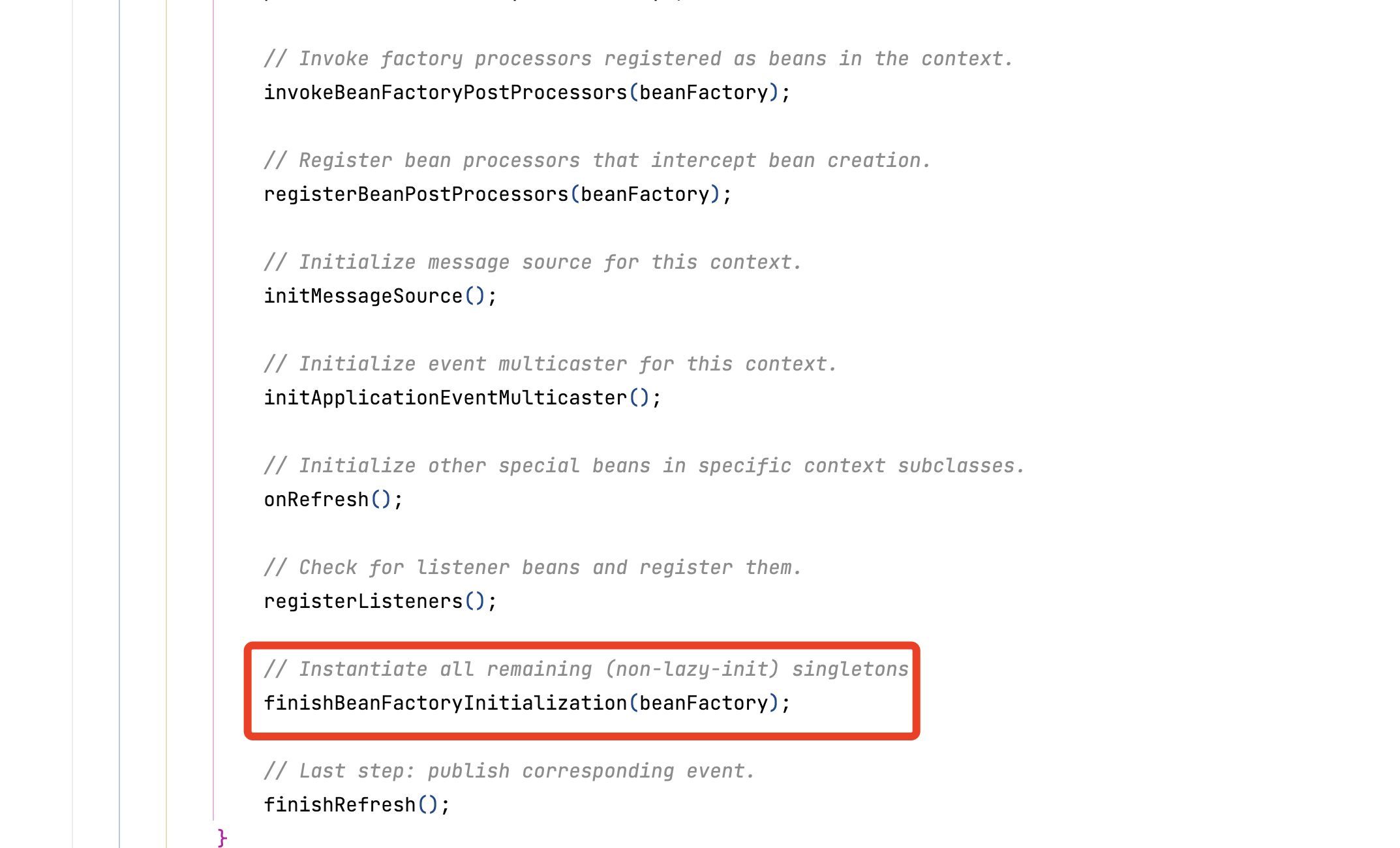
我们在跳进去finishBeanFactoryInitialization(beanFactory)函数后内的preInstantiateSingletons函数,这个函数的作用是预创建所有的单例Bean。也就是说容器启动时加载Bean的地方。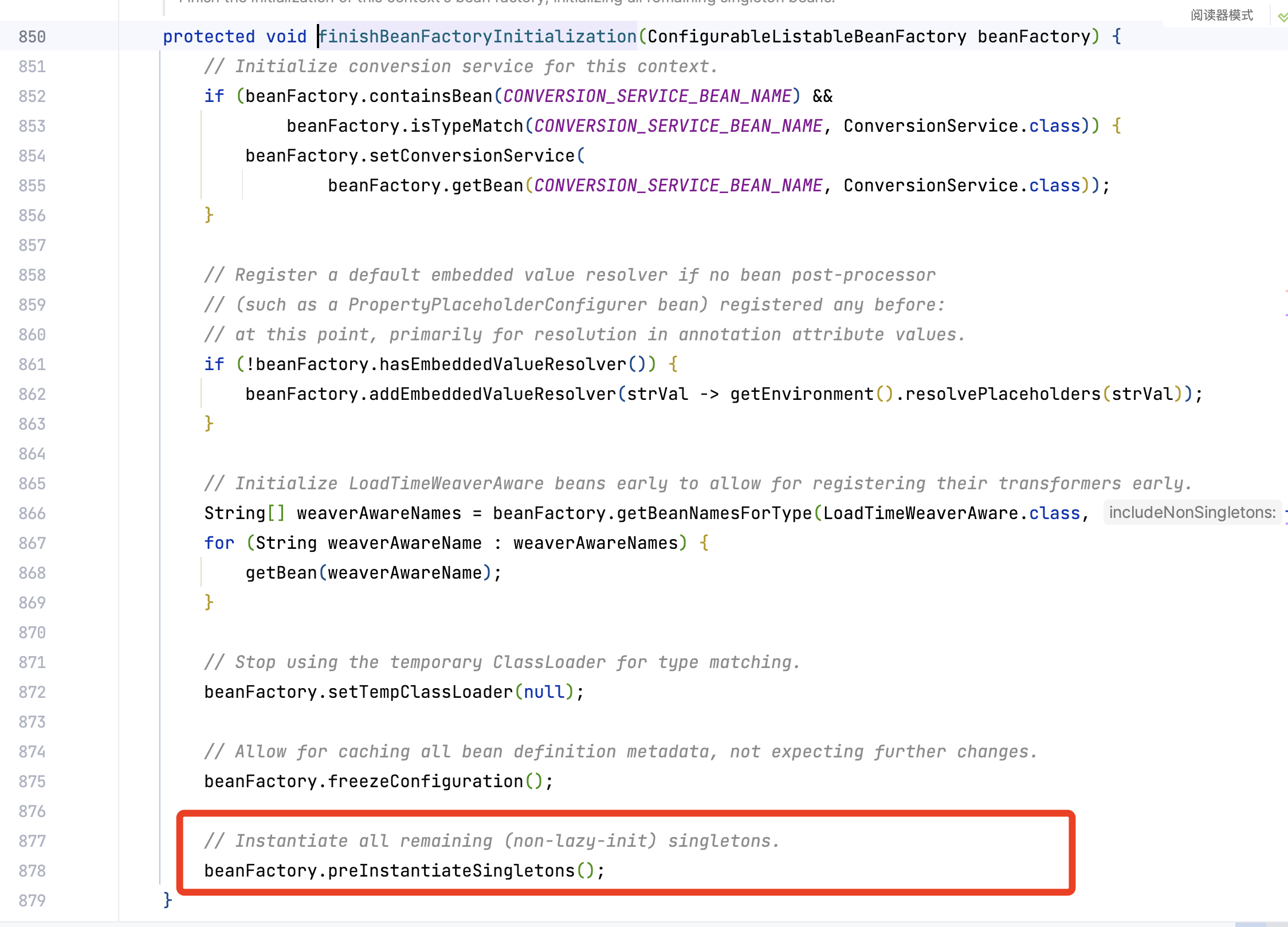
找到AService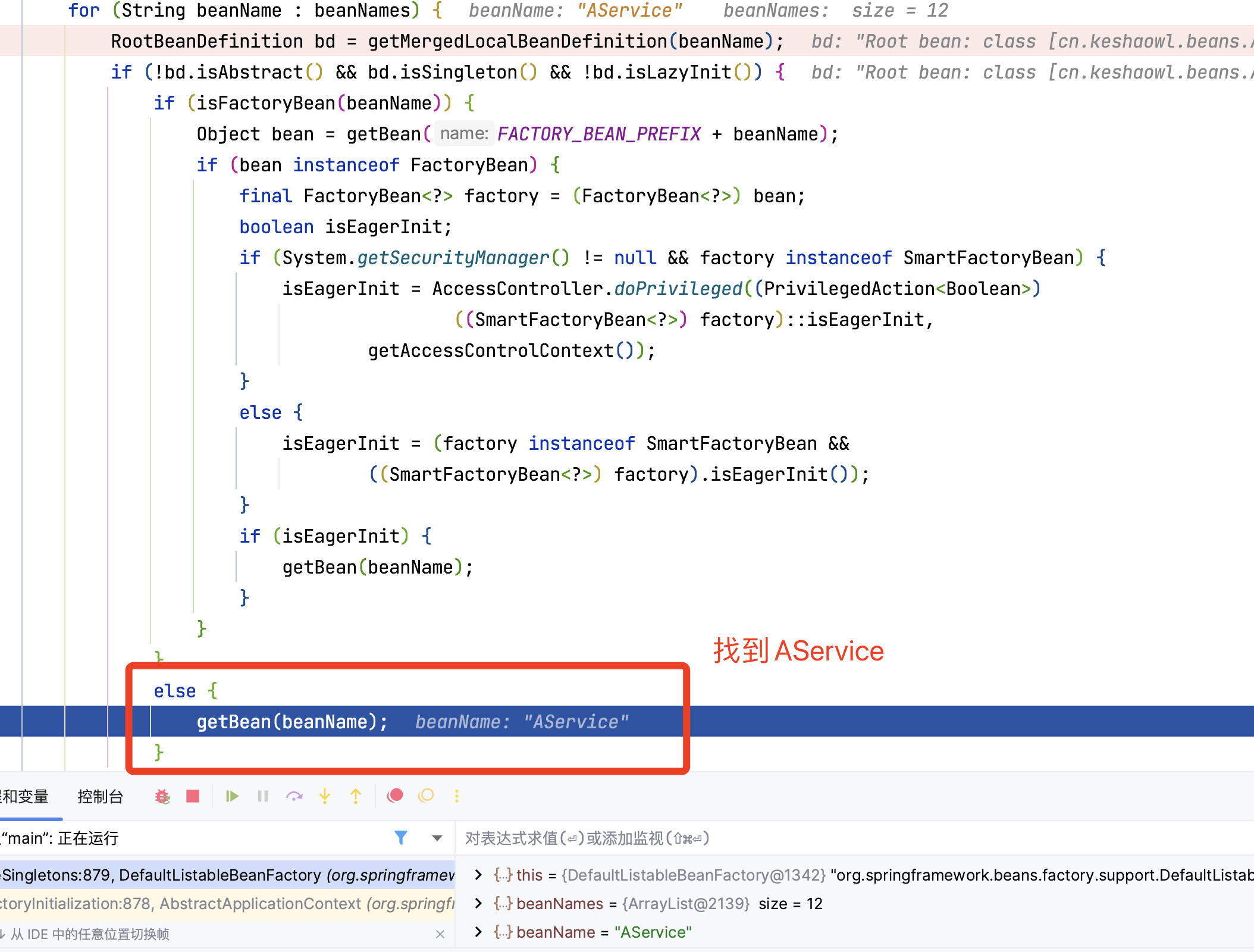
第一层

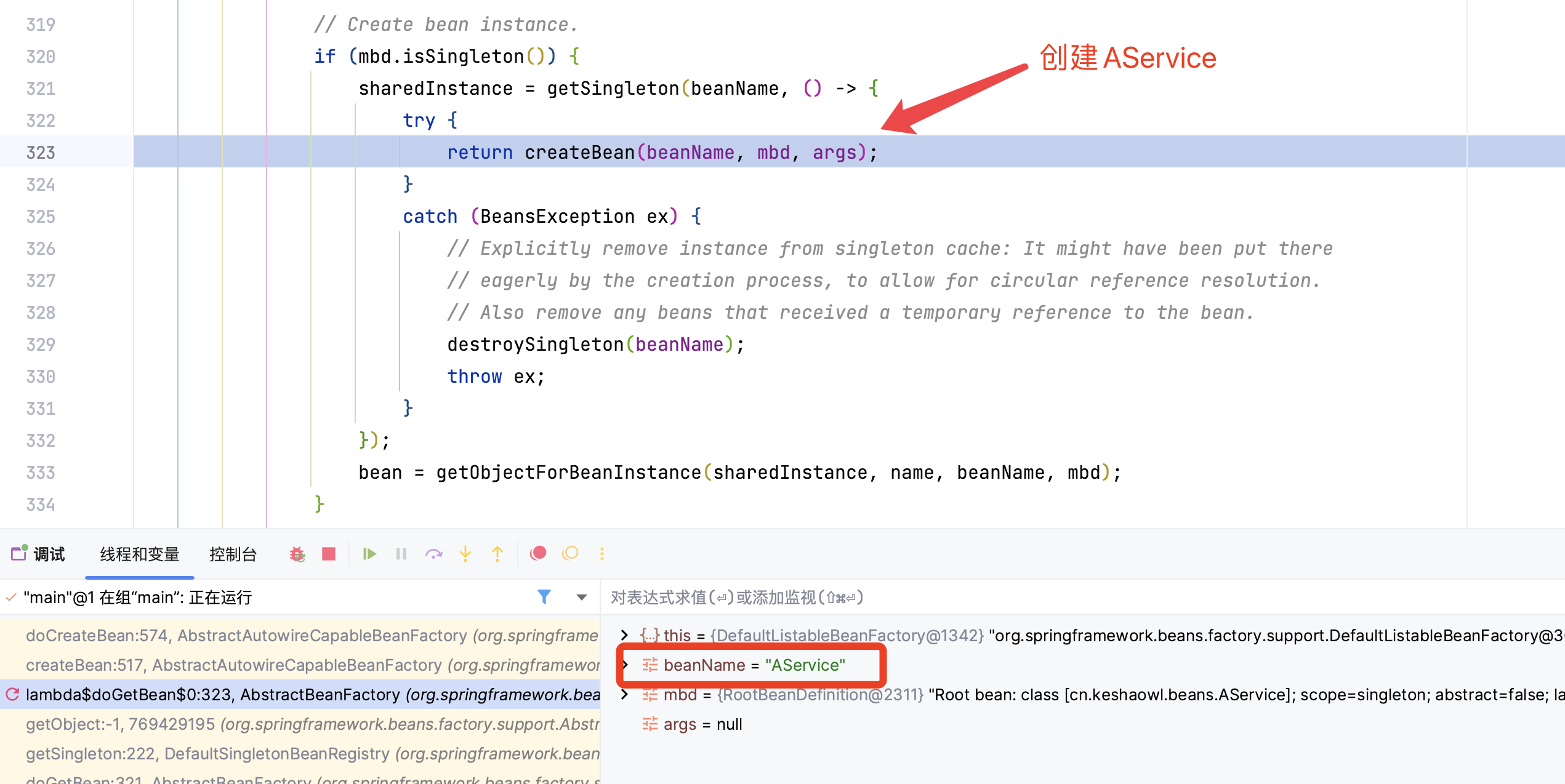
createBean 创建AService
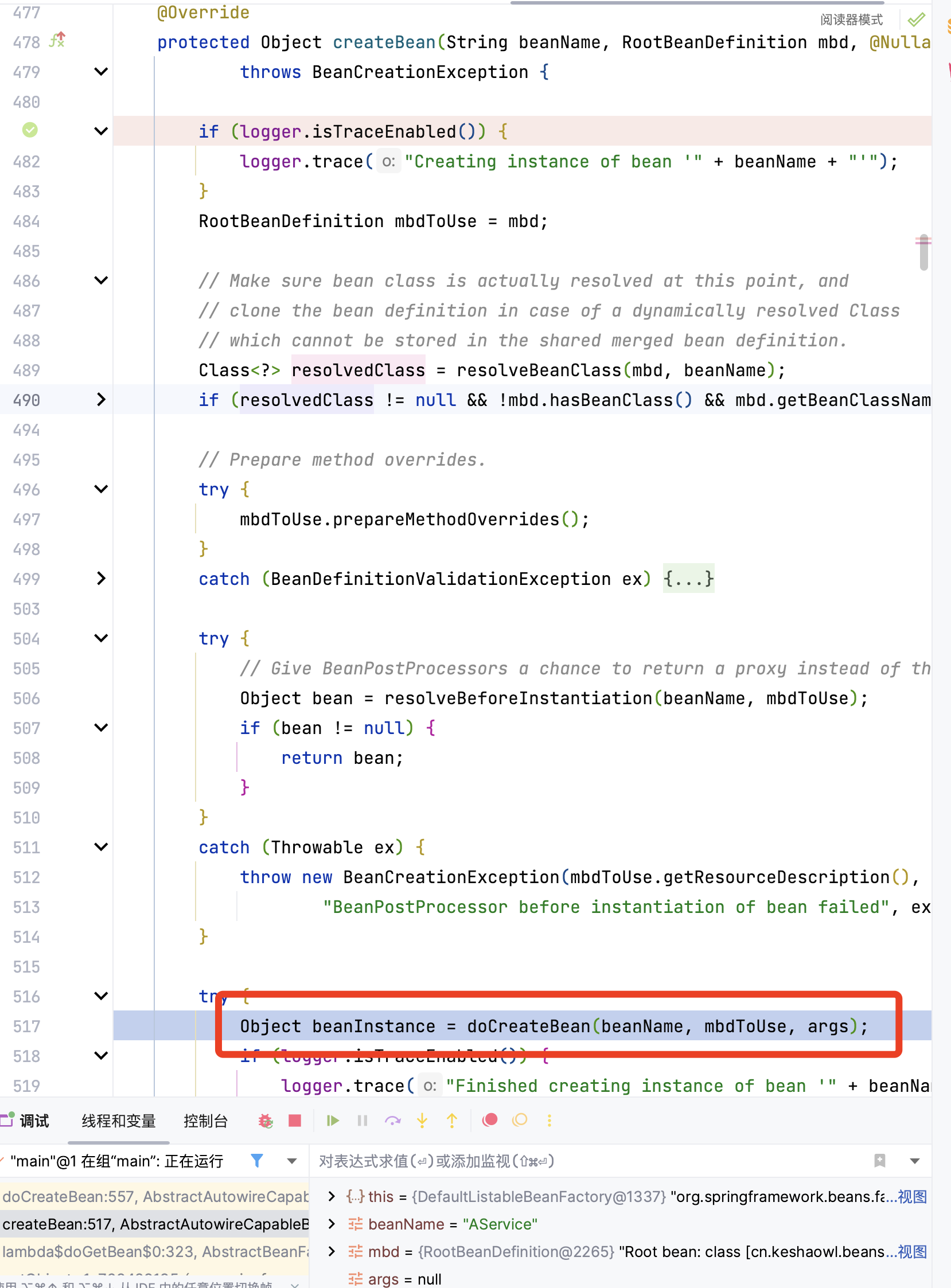
又去调用doCreateBean
调用 addSingletonFactory() (放入三级缓存)
进入 doCreateBean() 后,调用 addSingletonFactory()
在这个函数中还做了创建Bean的实例,createBeanInstance
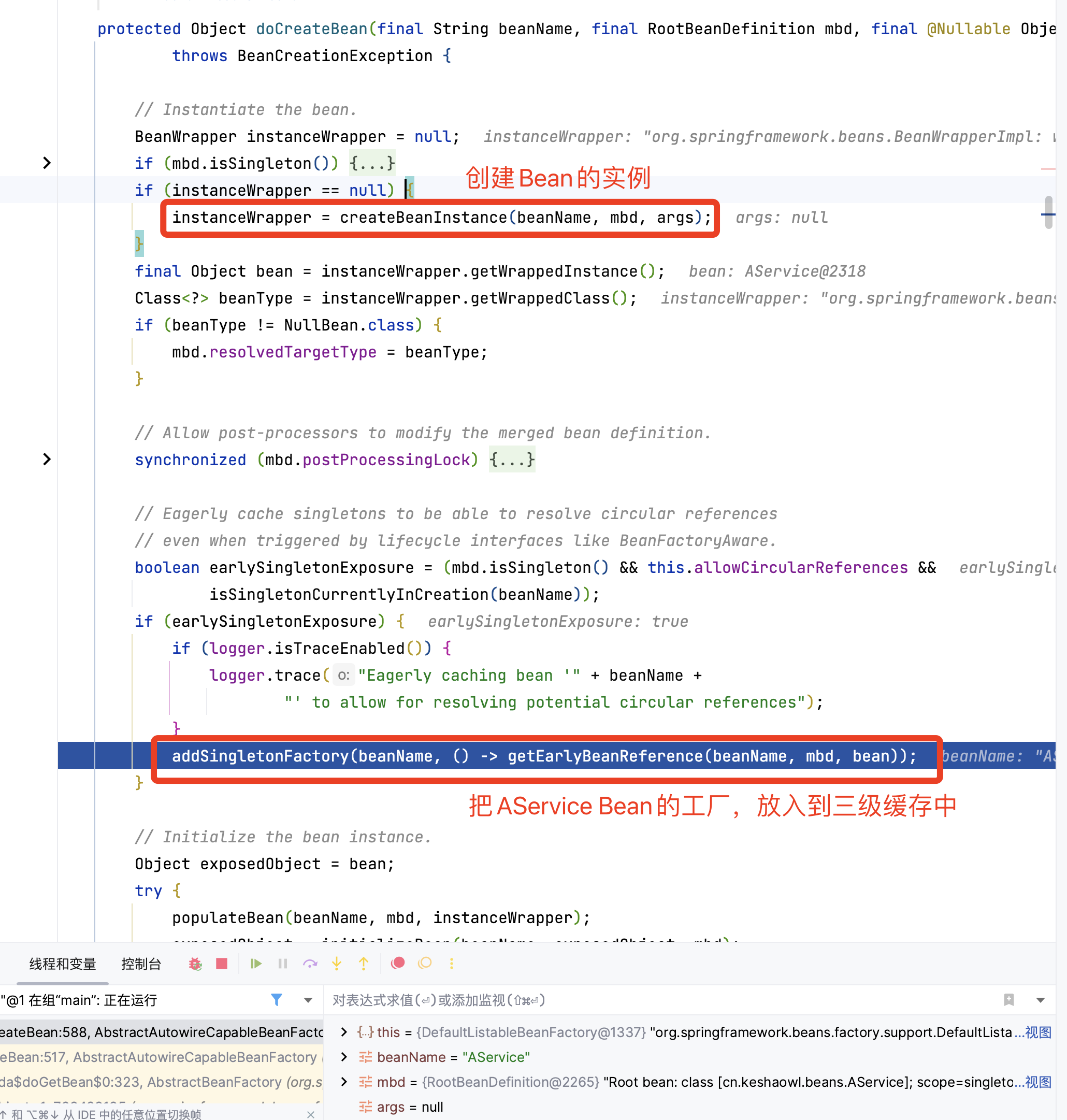
查看是否放入三级缓存
我们查看下是否放入到了三级缓存中了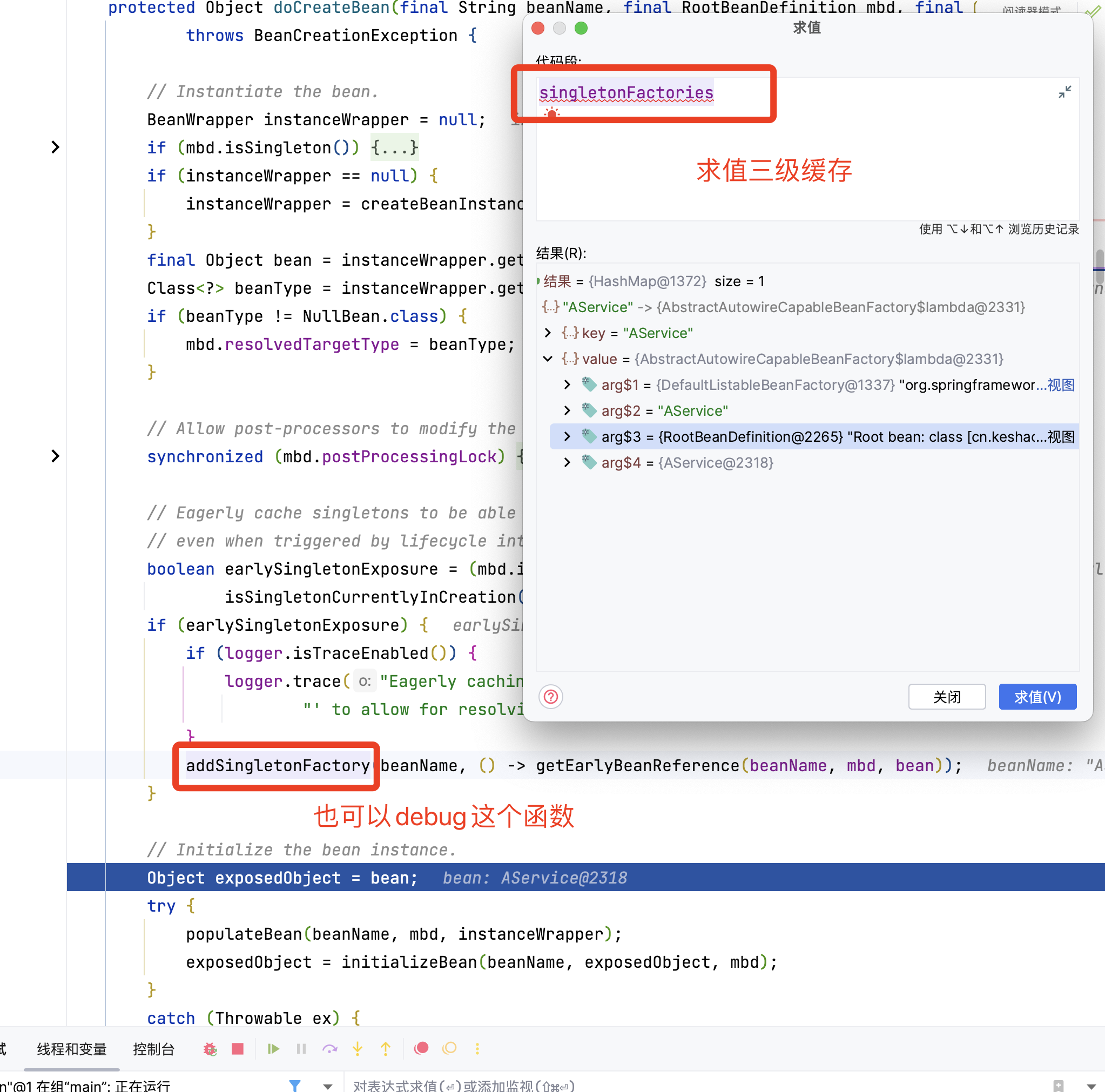
通过条件表达式可以看出来确实放入了三级缓存中
addSingletonFactory函数如下:

进入populateBean属性注入
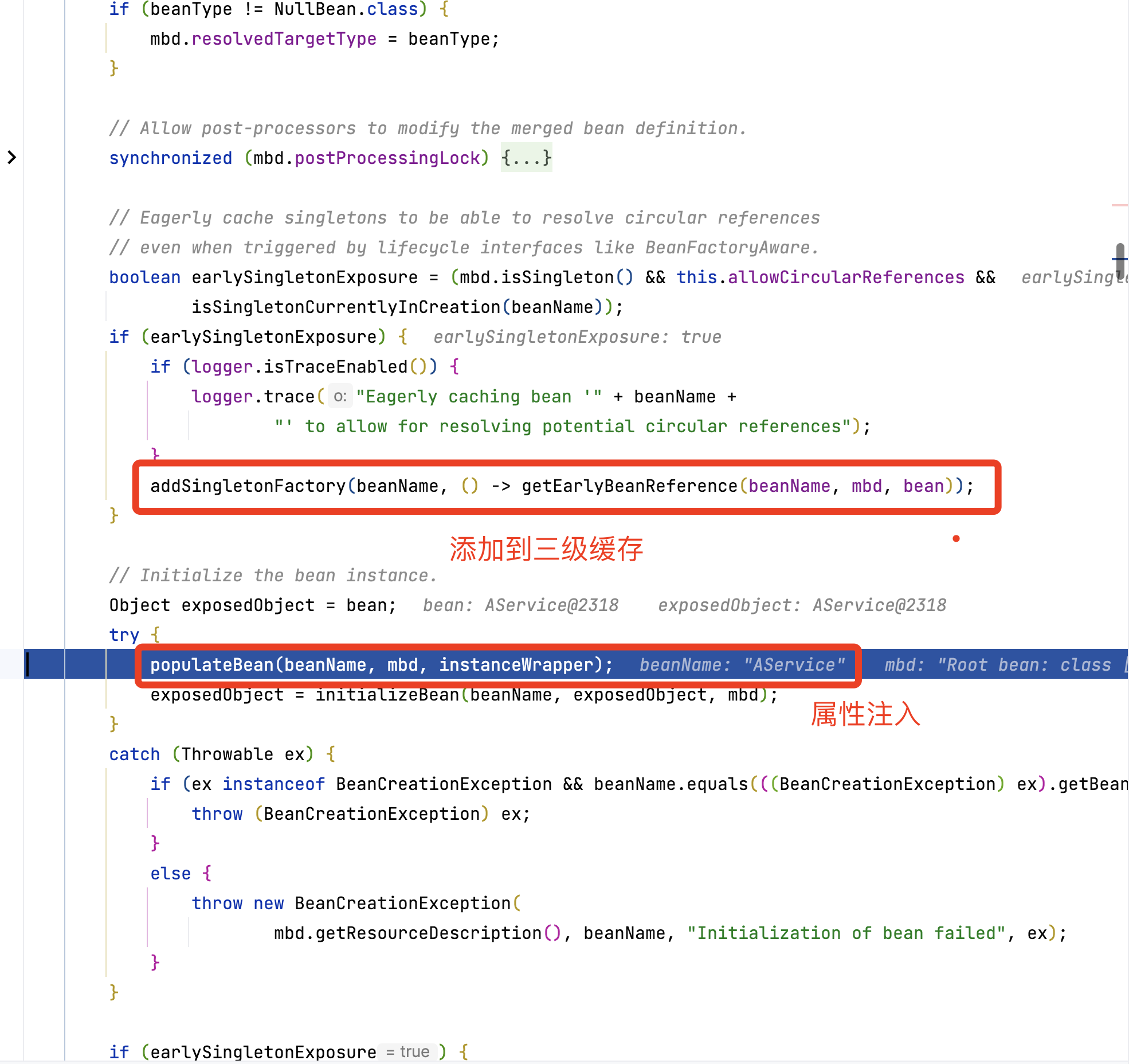
执行 postProcessProperties()
进入到 populateBean(),执行 postProcessProperties(),这里是一个策略模式,找到下图的策略对象。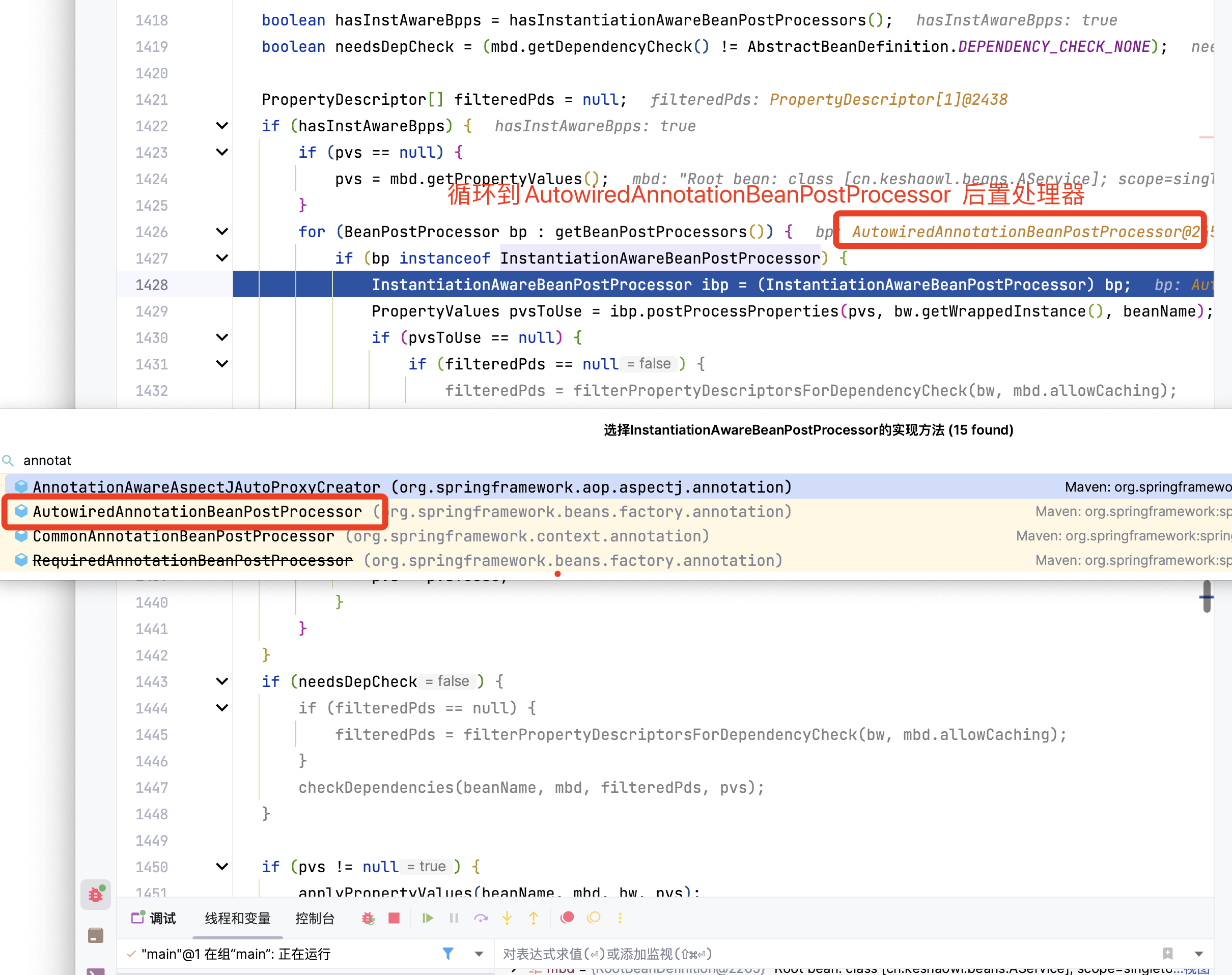
找到org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor#postProcessProperties后,我们简单查看下元数据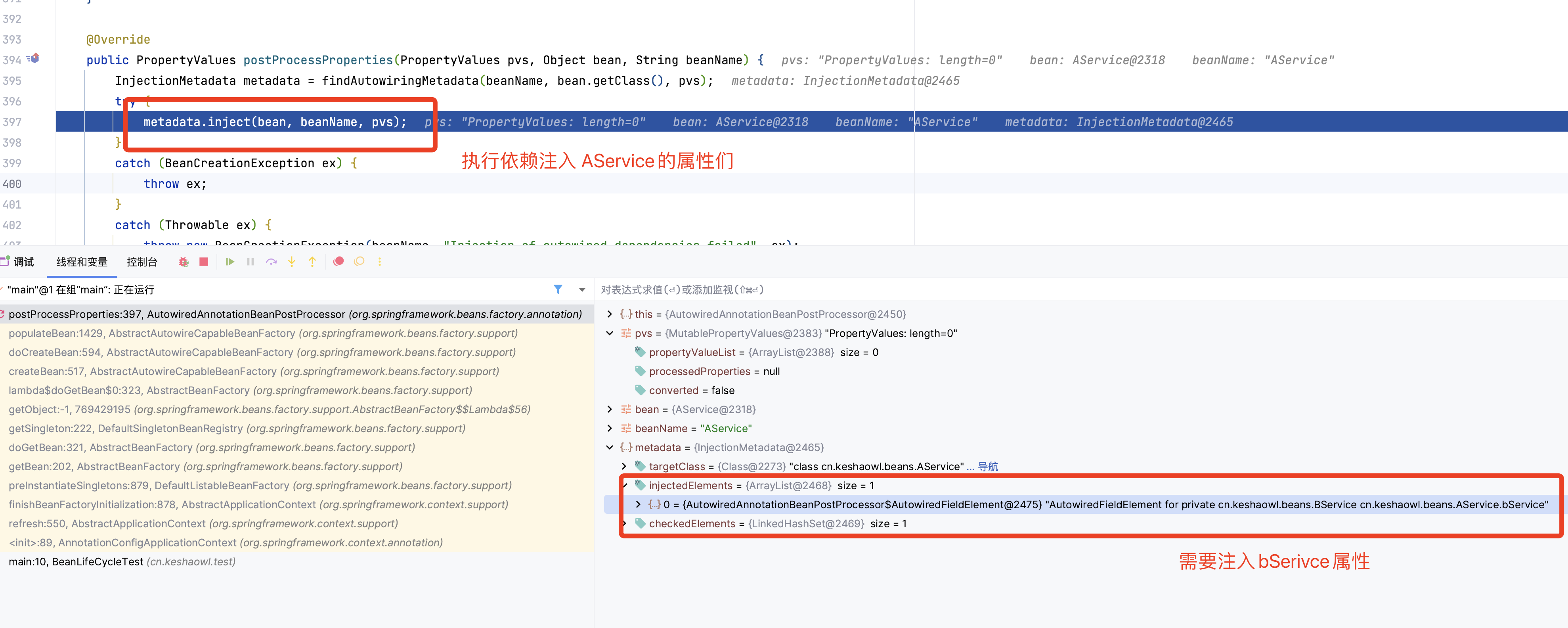
执行依赖注入属性 inject()
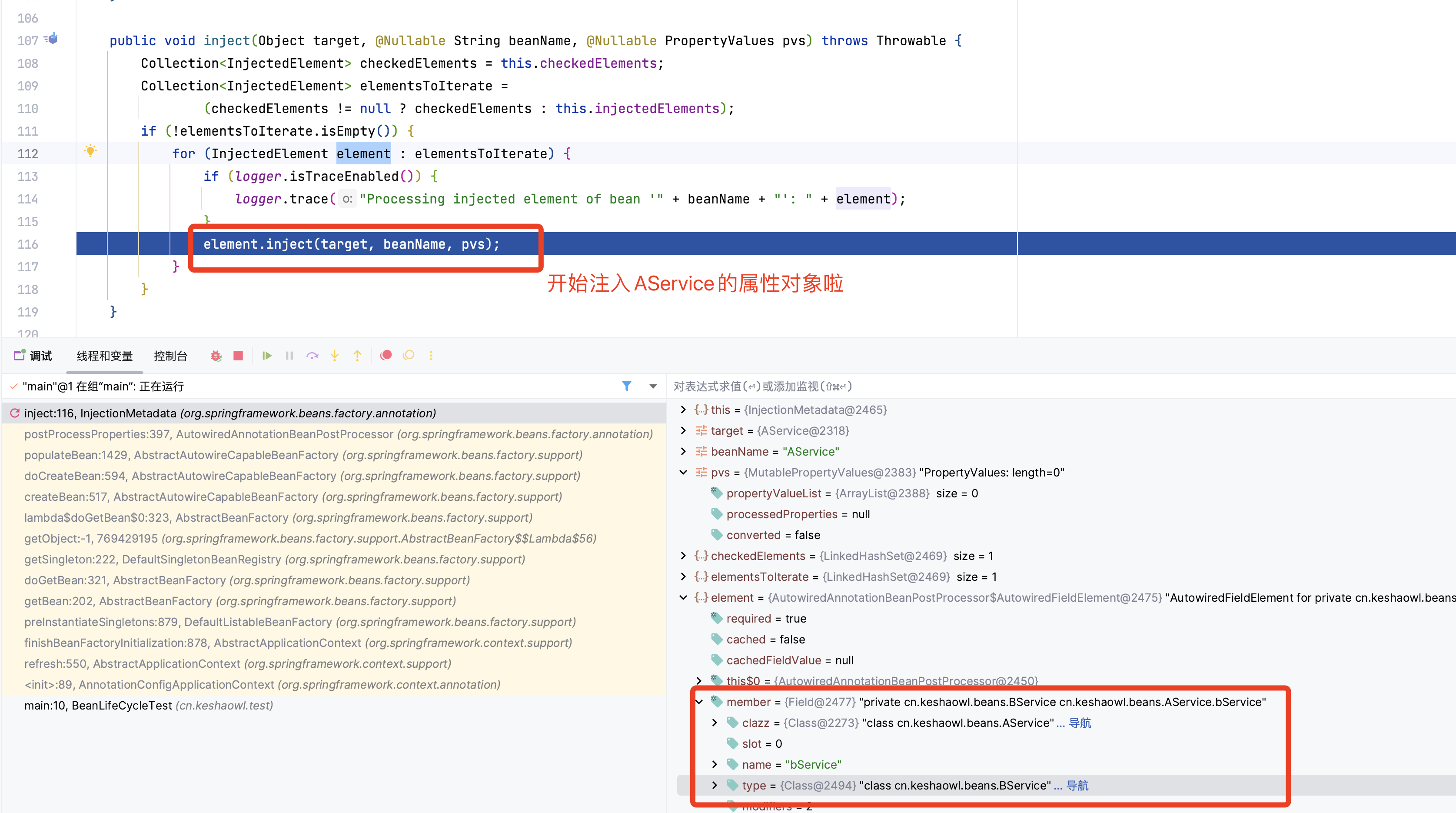
下面的流程都是为了获取AService的成员对象,然后进行注入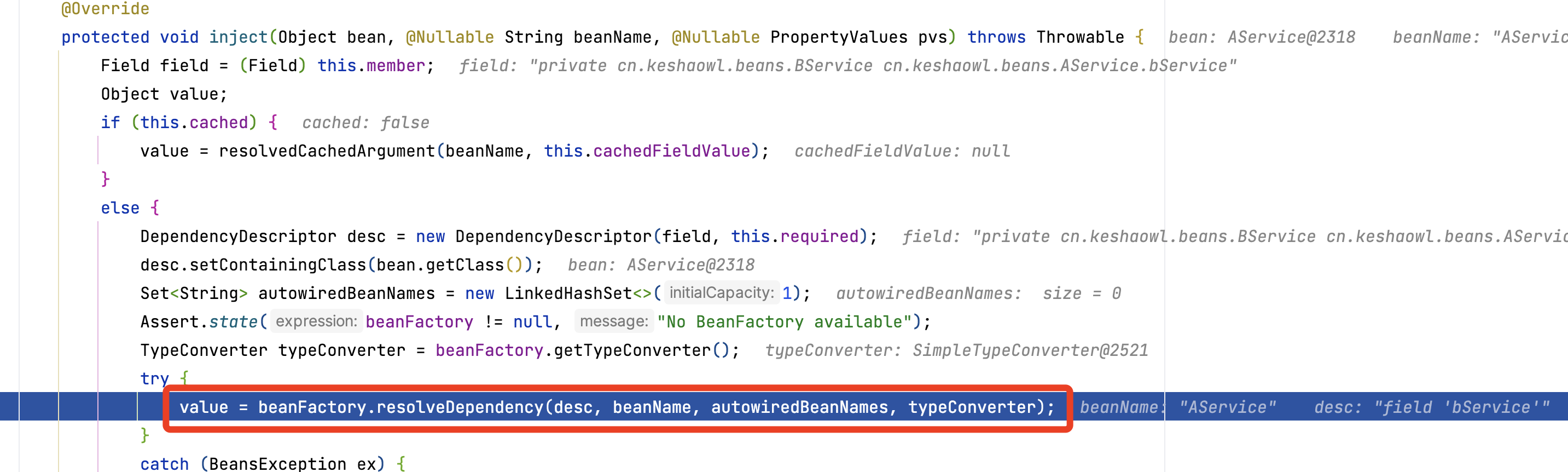
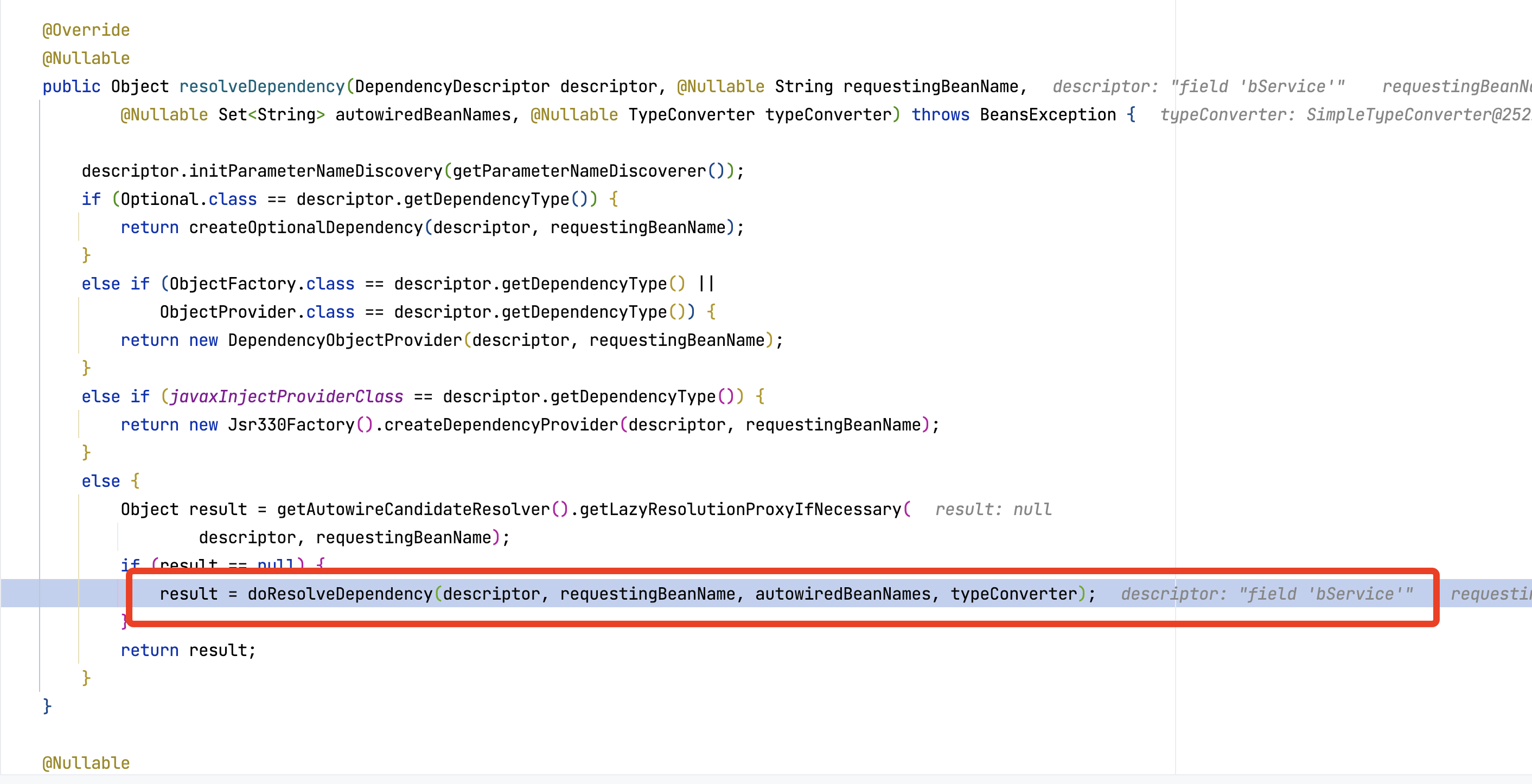
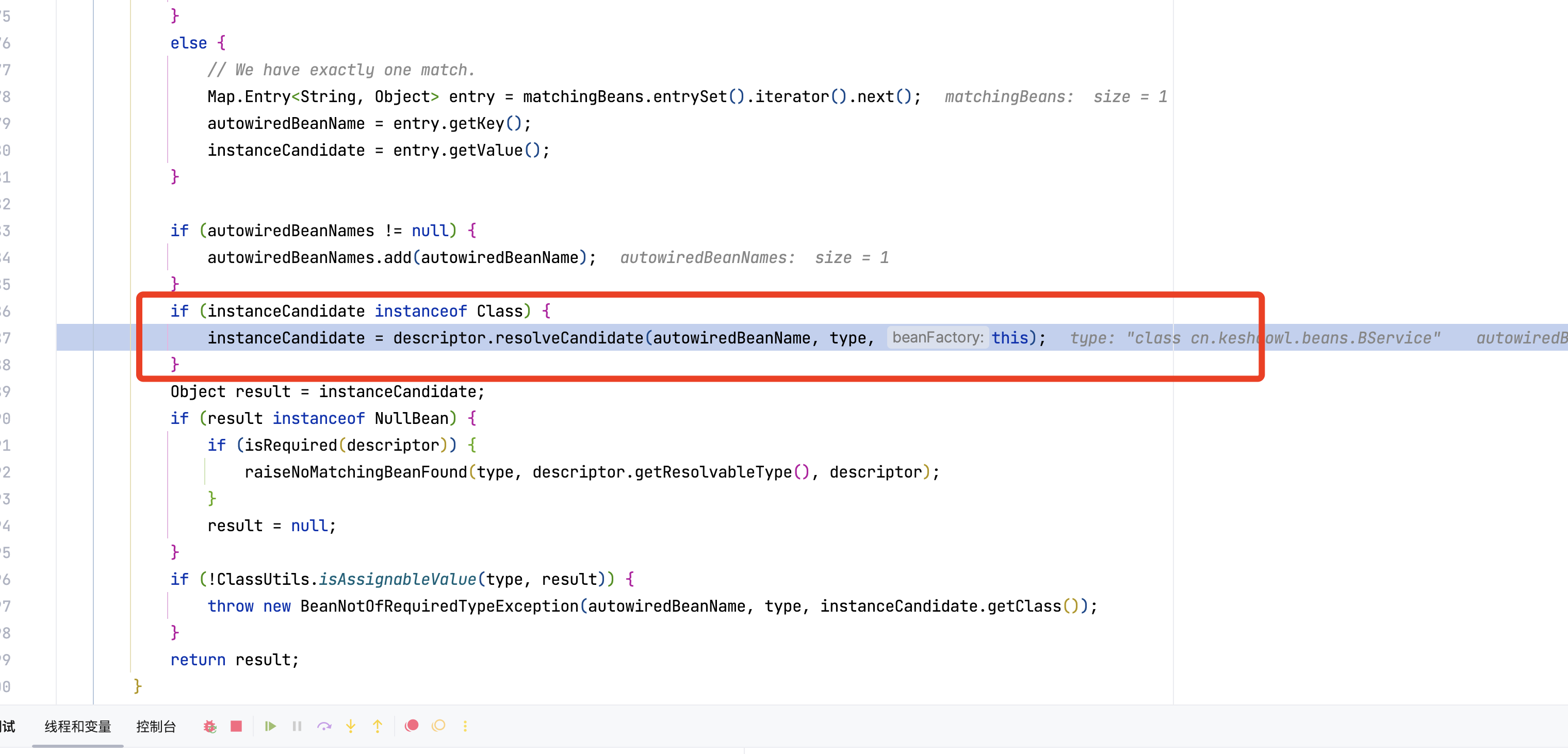
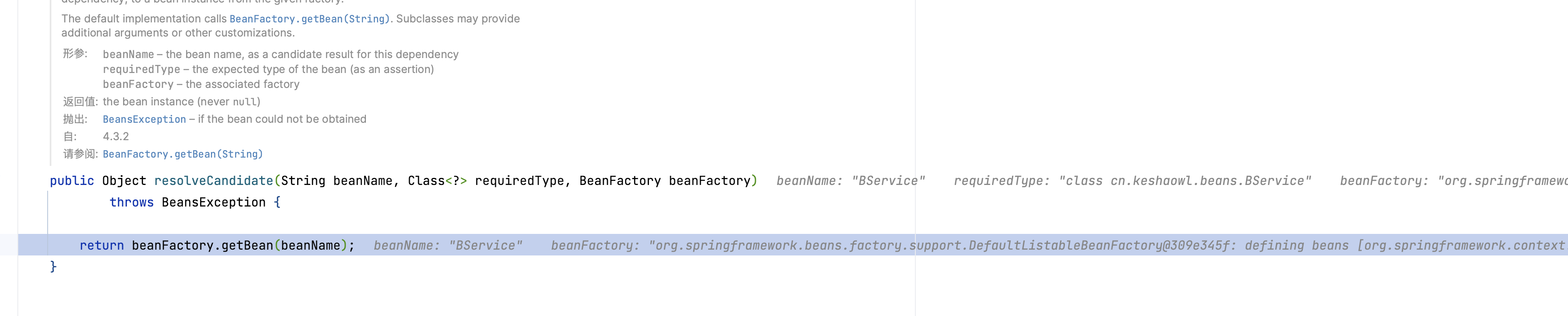

到这里,基本第一层就执行完了。应该去执行getBea(BService)的逻辑了
第二层

doResolveDependency()
获取BService的bean,从doGetBean(),到doResolveDependency(),和第一层逻辑完全一样,好到 BService依赖的对象名 AService
前面流程一样的,直接到org.springframework.beans.factory.support.DefaultListableBeanFactory#doResolveDependency就可以啦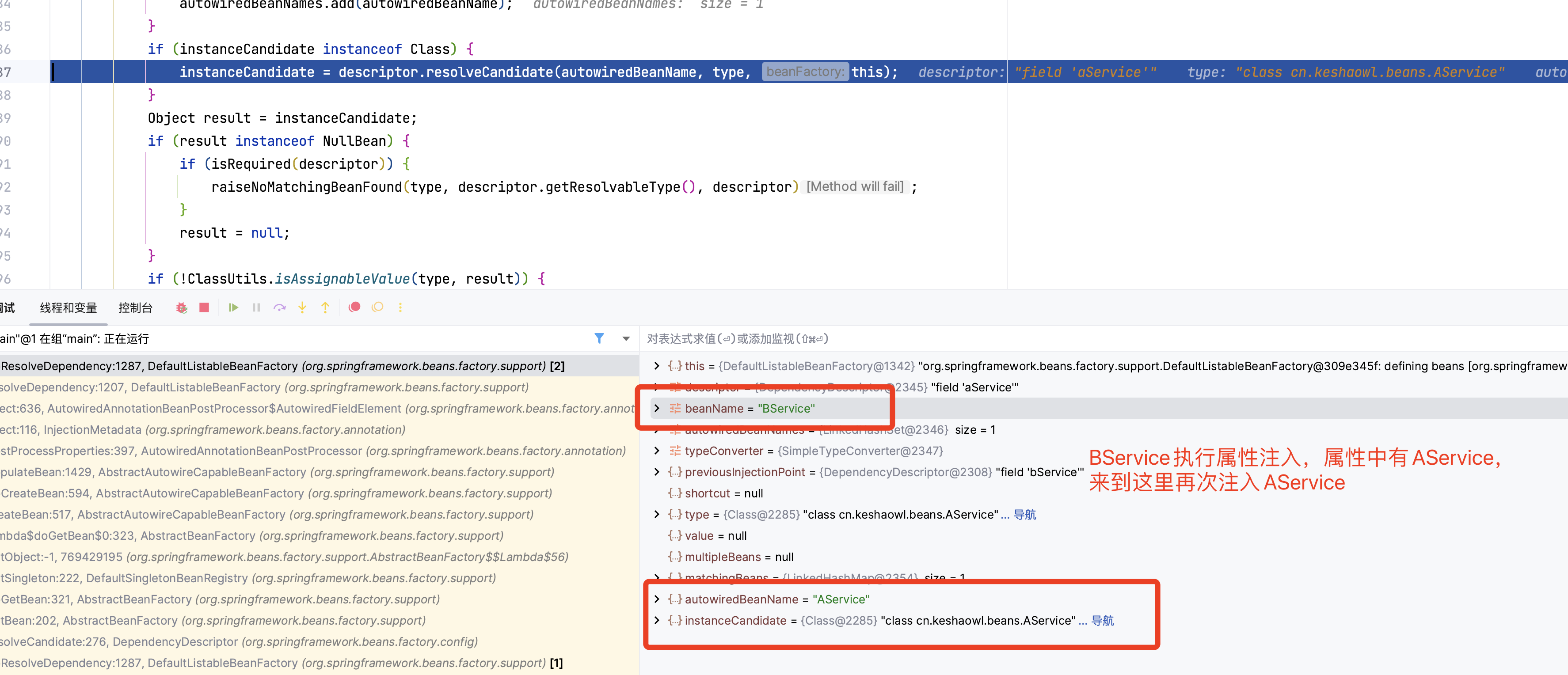
再次获取AService的Bean
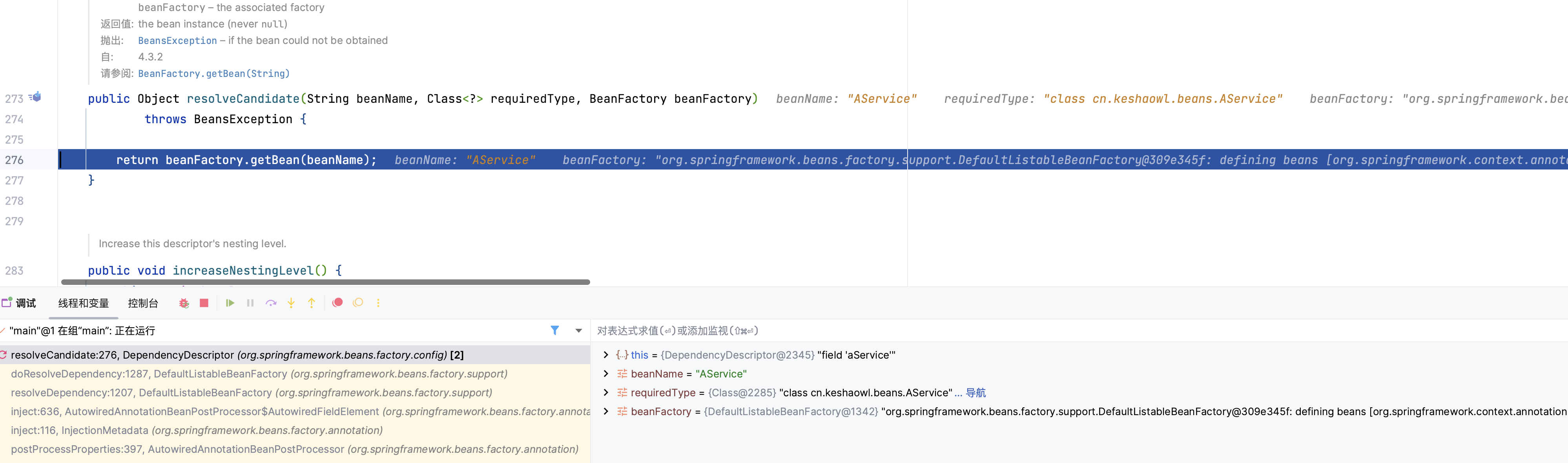
到这里,第二层基本已经完成了。需要再次进入到第三次套娃,啊哈哈
第三层

在第一层和第二层中,我们每次都会从 getSingleton() 获取对象,但是由于之前没有初始化 louzai1 和 louzai2 的三级缓存,所以获取对象为空。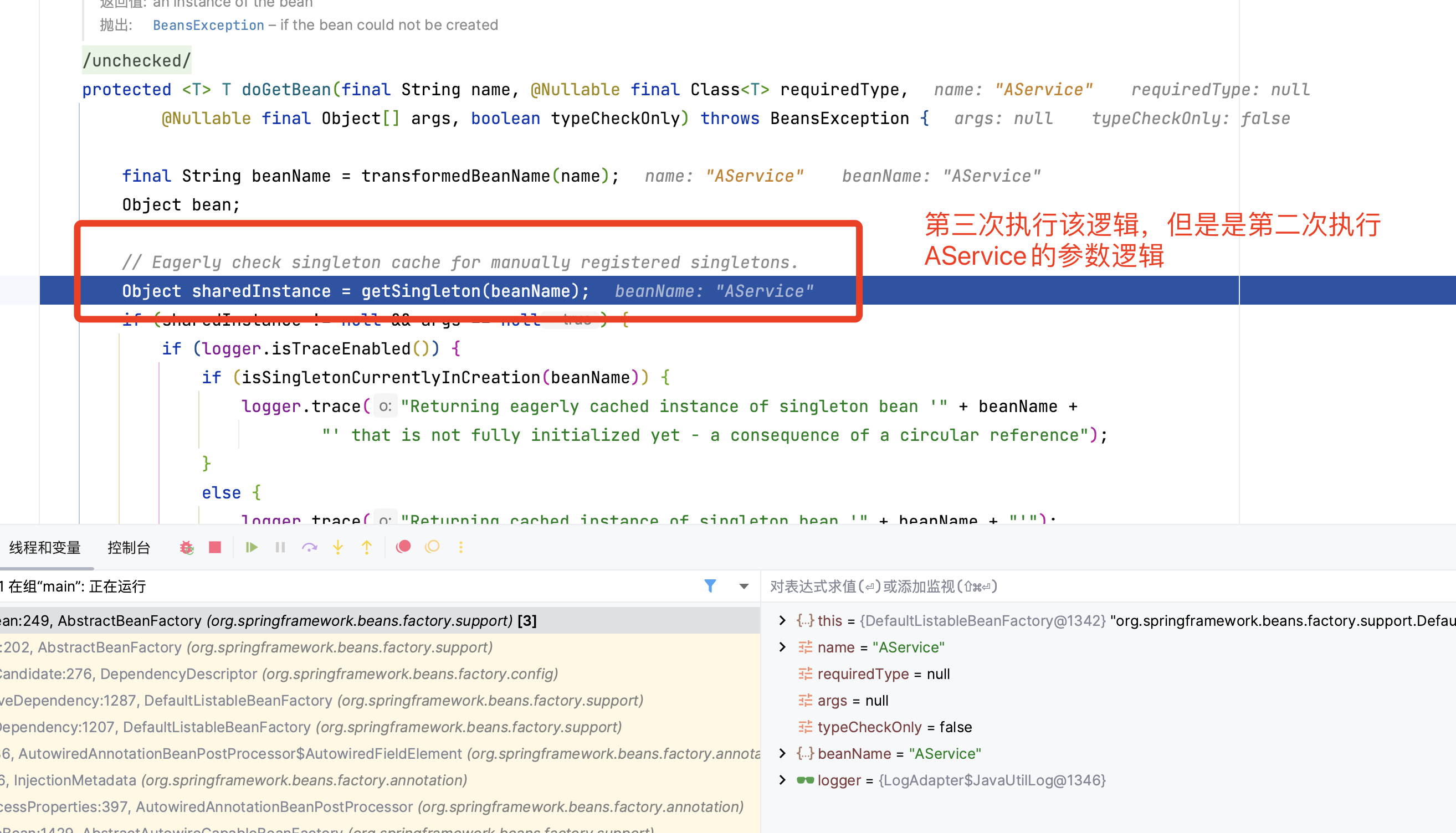
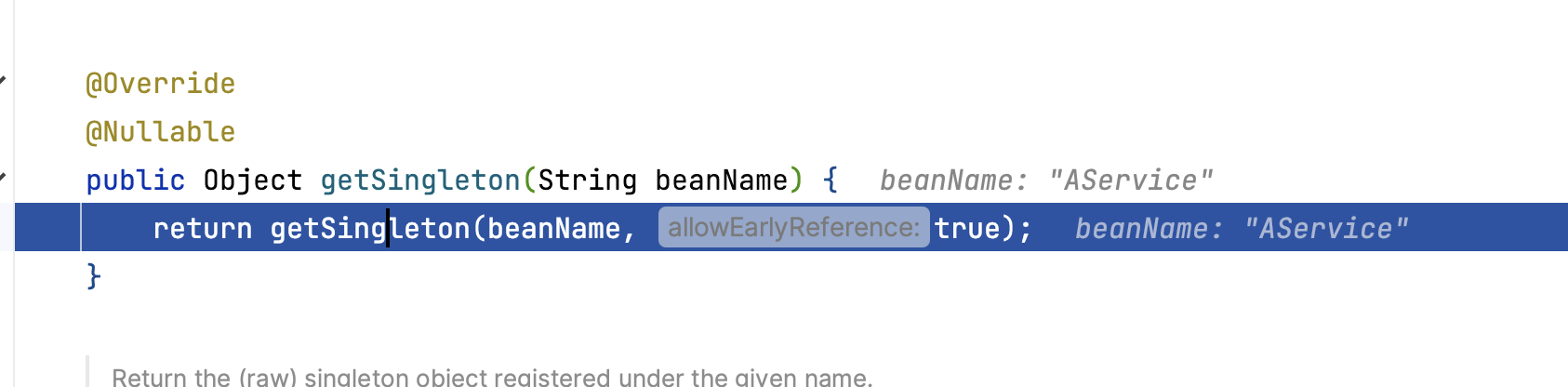
到了第三层,由于第三级缓存有 AService 数据,这里使用三级缓存中的工厂,为 AService 创建一个代理对象,塞入二级缓存。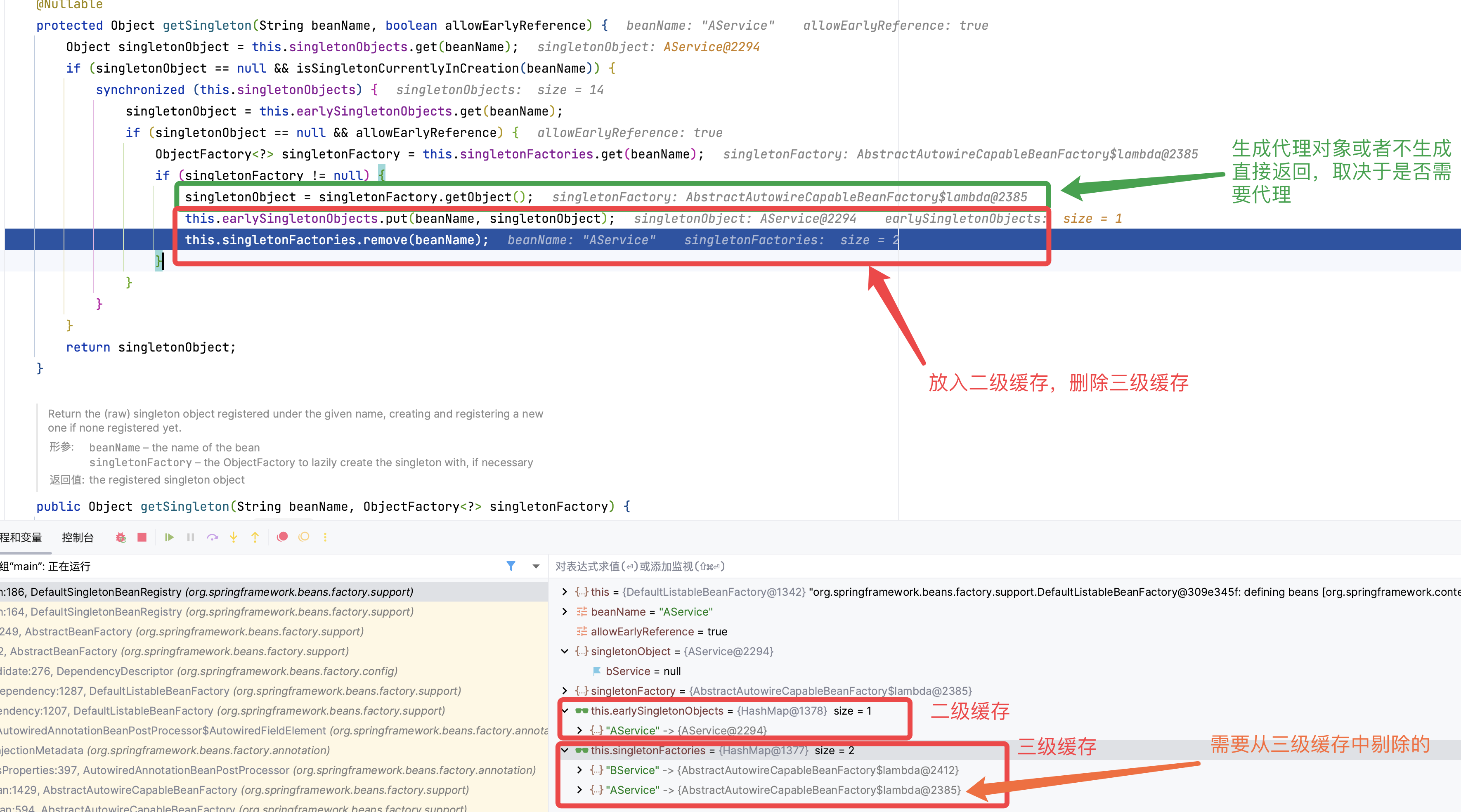
这里就拿到了AService的对象,解决了BService的依赖关系,返回到第二层。
返回第二层
返回到第二层后,BService的初始化结束,这里就结束了么?二级缓存的数据,啥时候会给到一级呢?
答案来了,在 doGetBean() 中,我们会通过 createBean() 创建一个 BService 的 bean,当 BService 的 bean 创建成功后,我们会执行 getSingleton(),它会对 BService 的结果进行处理。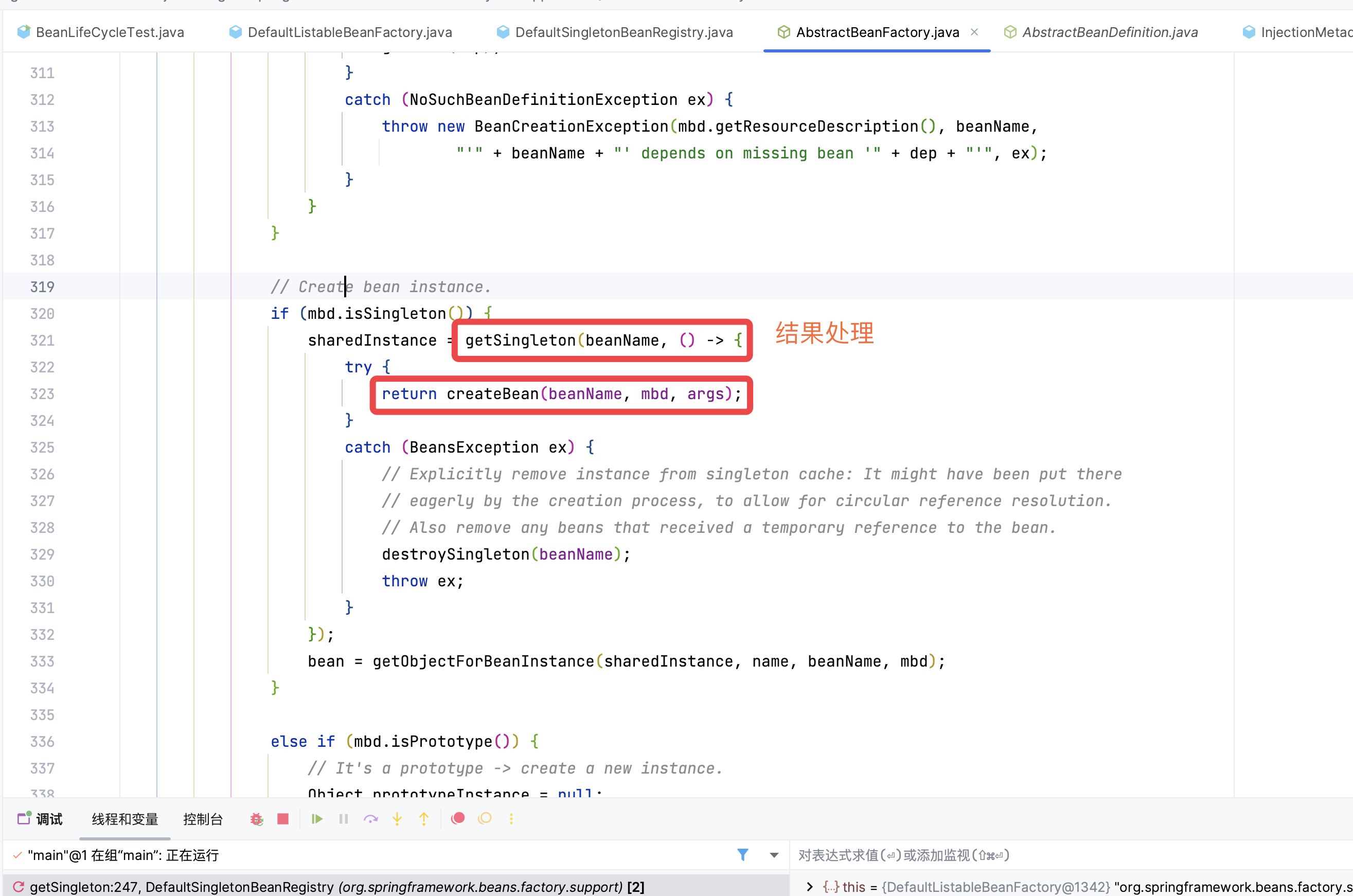
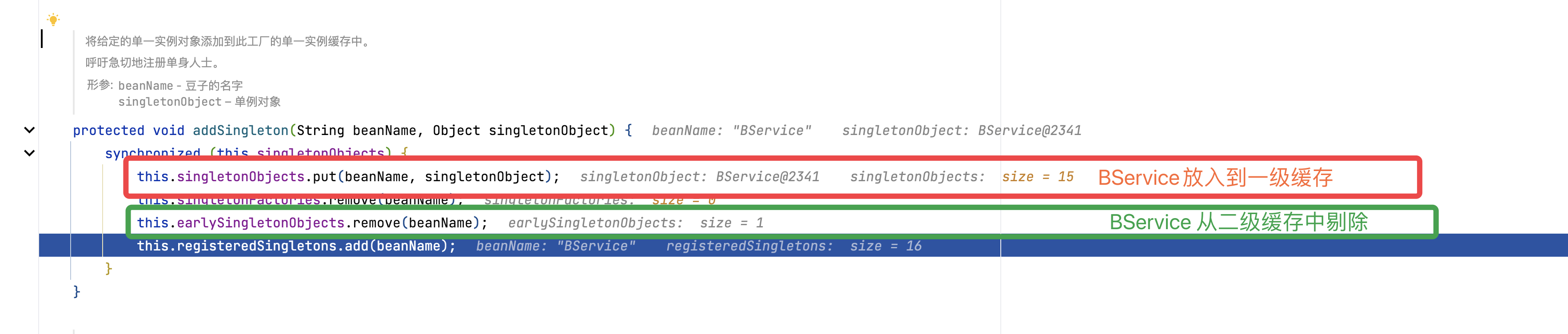
返回第一层
在AServic初始化完成后,会把AService的二级缓存清除,并将对象放入一级缓存中。至此依赖循环解决完毕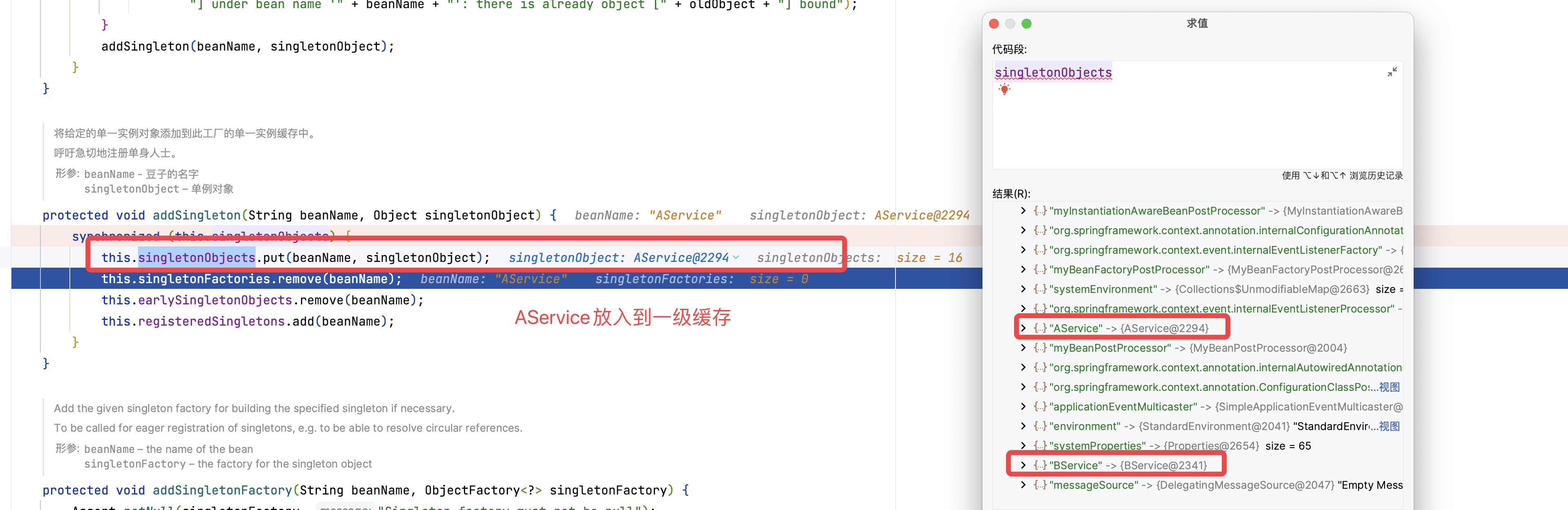
原理总结
为什么要有三级缓存?
我们先说“一级缓存”的作用,变量命名为 singletonObjects,结构是 Map<String, Object>,它就是一个单例池,将初始化好的对象放到里面,给其它线程使用,如果没有第一级缓存,程序不能保证 Spring 的单例属性。
“二级缓存”先放放,我们直接看“三级缓存”的作用,变量命名为 singletonFactories,结构是 Map<String, ObjectFactory<?>>,Map 的 Value 是一个对象的代理工厂,所以“三级缓存”的作用,其实就是用来存放对象的代理工厂。
那这个对象的代理工厂有什么作用呢,我先给出答案,它的主要作用是存放半成品的单例 Bean,目的是为了“打破循环”,可能大家还是不太懂,这里我再稍微解释一下。
我们回到文章开头的例子,创建 A 对象时,会把实例化的 A 对象存入“三级缓存”,这个 A 其实是个半成品,因为没有完成 A 的依赖属性 B 的注入,所以后面当初始化 B 时,B 又要去找 A,这时就需要从“三级缓存”中拿到这个半成品的 A(这里描述,其实也不完全准确,因为不是直接拿,为了让大家好理解,我就先这样描述),打破循环。
那我再问一个问题,为什么“三级缓存”不直接存半成品的 A,而是要存一个代理工厂呢 ?答案是因为 AOP。
在解释这个问题前,我们看一下这个代理工厂的源码,让大家有一个更清晰的认识。
直接找到创建 A 对象时,把实例化的 A 对象存入“三级缓存”的代码,直接用前面的两幅截图。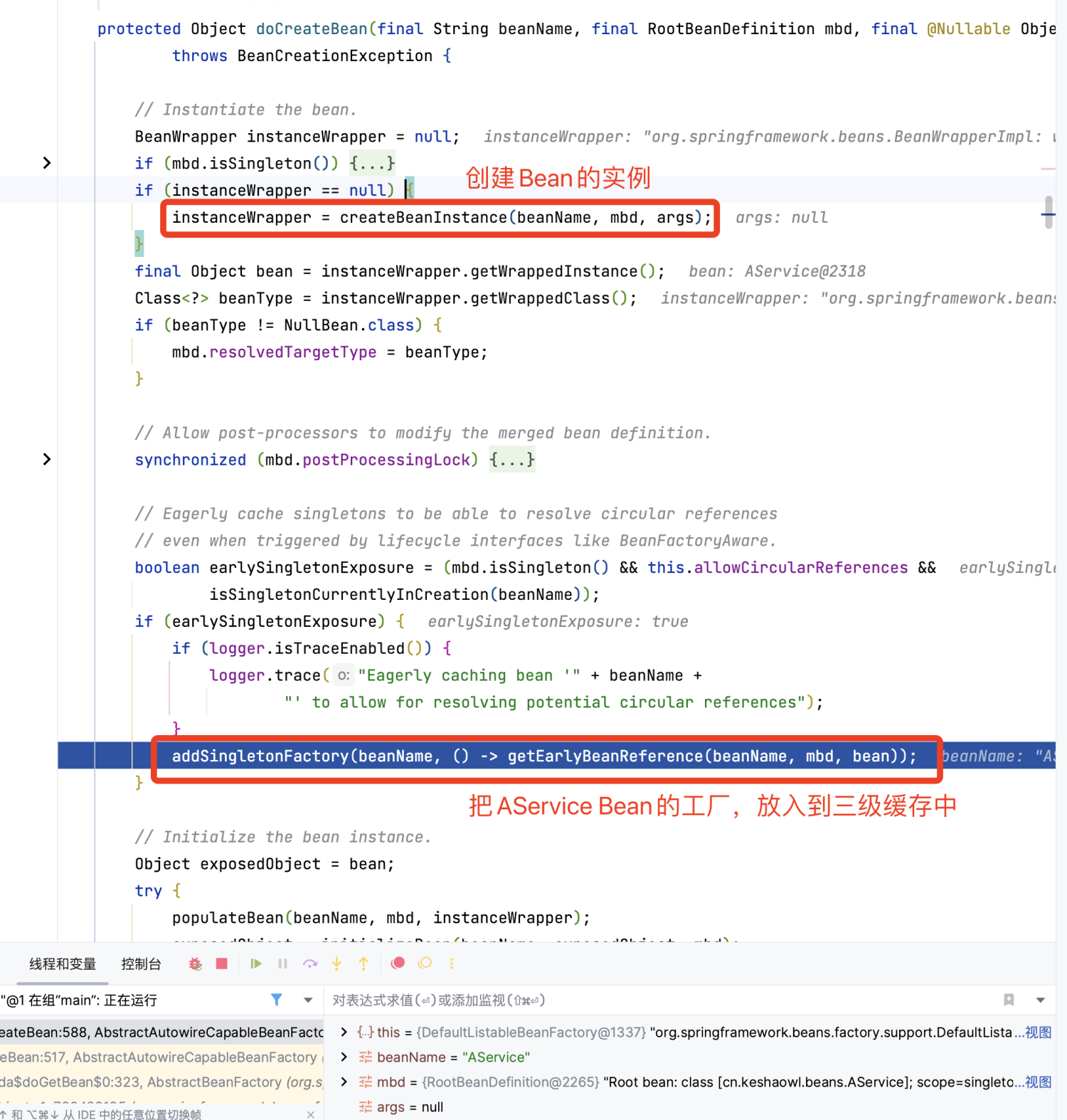
下面我们主要看这个对象工厂是如何得到的,进入 getEarlyBeanReference() 方法。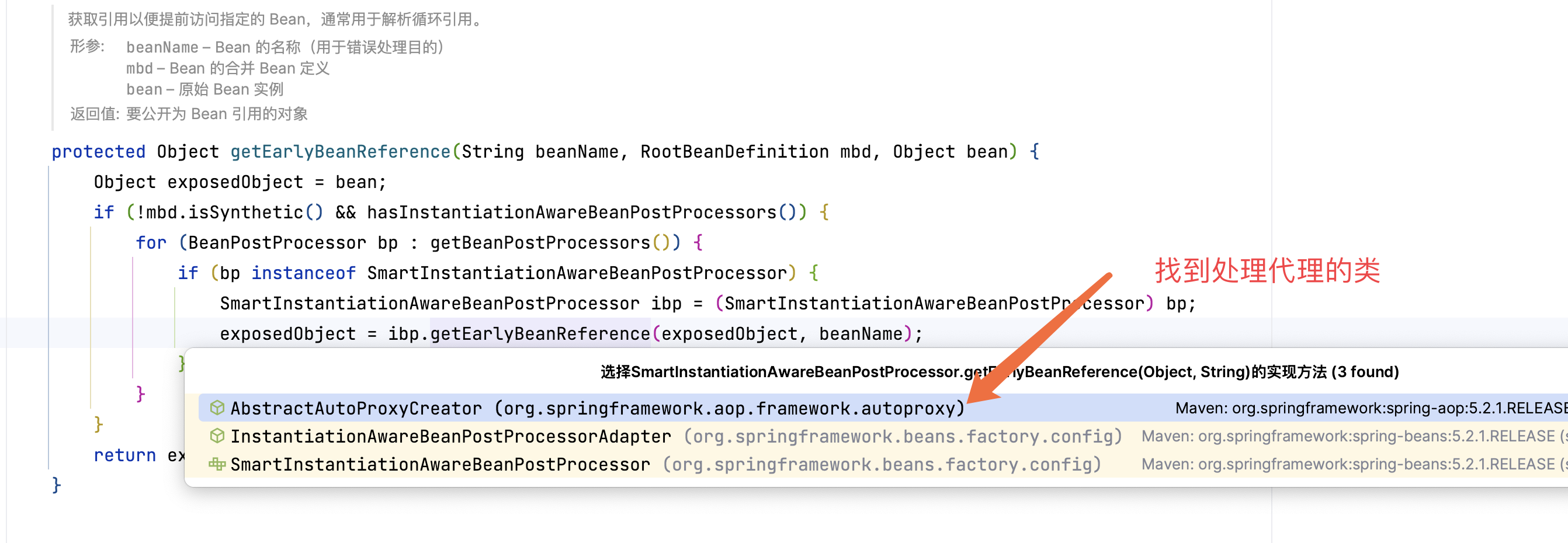
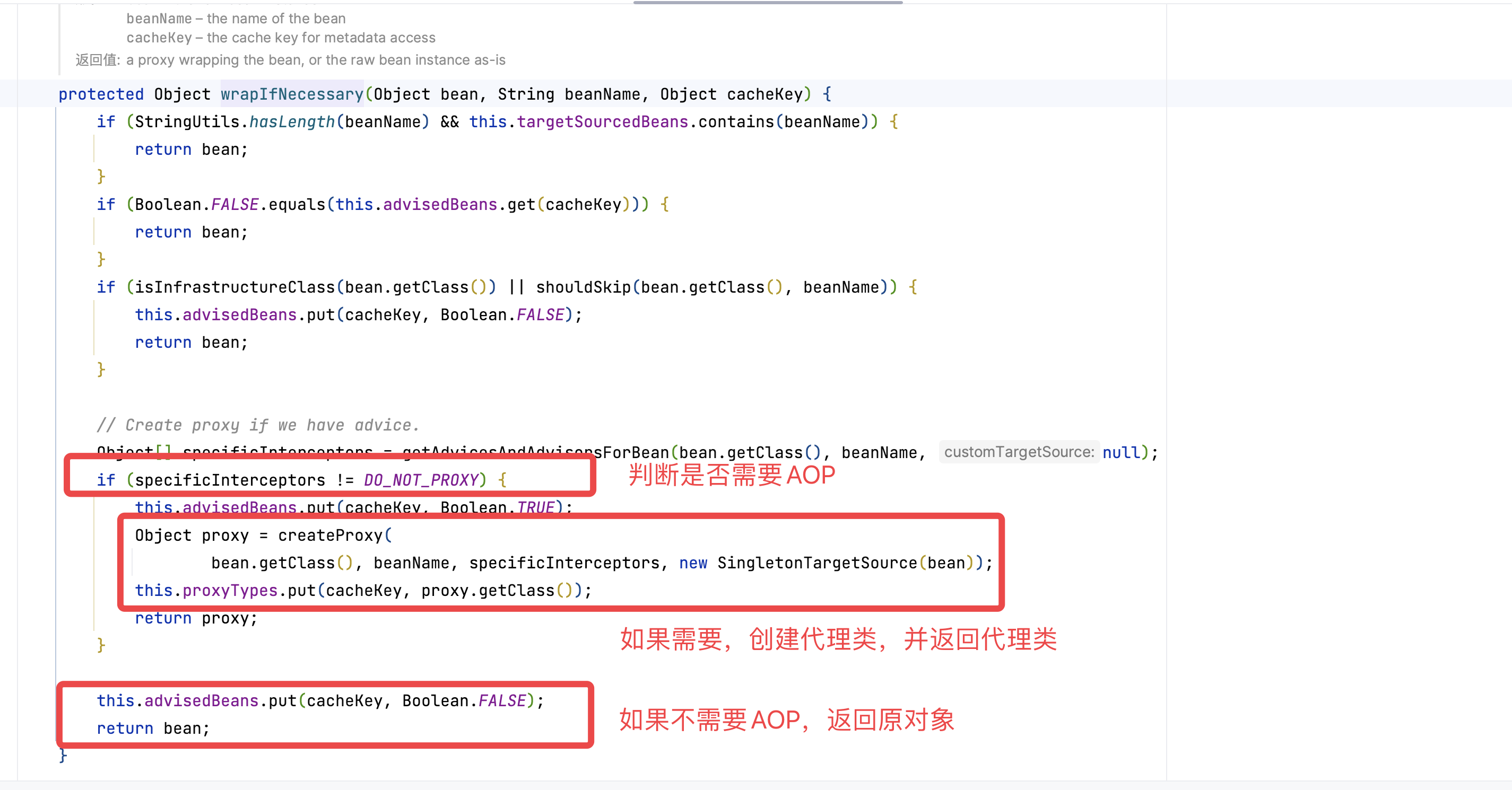
最后一幅图太重要了,我们知道这个对象工厂的作用:
- 如果 A 有 AOP,就创建一个代理对象;
- 如果 A 没有 AOP,就返回原对象。
那“二级缓存”的作用就清楚了,就是用来存放对象工厂生成的对象,这个对象可能是原对象,也可能是个代理对象。
我再问一个问题,为什么要这样设计呢?把二级缓存干掉不行么 ?我们继续往下看。
能去掉第二级缓存吗?
1 |
|
根据上面的套娃逻辑,A 需要找 B 和 C,但是 B 需要找 A,C 也需要找 A。
假如 A 需要进行 AOP,因为代理对象每次都是生成不同的对象,如果干掉第二级缓存,只有第一、三级缓存:
- B 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A1。
- C 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A2。
看到问题没?你通过 A 的工厂的代理对象,生成了两个不同的对象 A1 和 A2,所以为了避免这种问题的出现,我们搞个二级缓存,把 A1 存下来,下次再获取时,直接从二级缓存获取,无需再生成新的代理对象。
所以“二级缓存”的目的是为了避免因为 AOP 创建多个对象,其中存储的是半成品的 AOP 的单例 bean。
如果没有 AOP 的话,我们其实只要 1、3 级缓存,就可以满足要求。
最后总结
我们再回顾一下 3 级缓存的作用:
- 一级缓存:为“Spring 的单例属性”而生,就是个单例池,用来存放已经初始化完成的单例 Bean;
- 二级缓存:为“解决 AOP”而生,存放的是半成品的 AOP 的单例 Bean;
- 三级缓存:为“打破循环”而生,存放的是生成半成品单例 Bean 的工厂方法。