
写在最前面
看到标题你可能会疑惑为什么不是30分钟?
因为我这个文章图文并茂,非常恐怖,兄弟,其实你不用30分钟就可以看懂。
你可能会以为我在吹牛B,但是当你看完的时候,一掐表,你会发现
我真的是在吹牛B
那又为什么是.22呢?
作为一个理科生,保留两位小数是不变的信仰。
而在下,仅仅是喜欢2这个数字,如是而已
正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换、校验那些符合某个模式(规则)的文本。
RegExp对象
在爪洼死苦瑞per特中,RegExp 对象表示正则表达式,它是对字符串执行模式匹配的强大工具。
那么要如何使用呢?
两种方式:字面量,构造函数
1 | var reg = /\bhello\b/g //字面量 |
1 | var reg = new RegExp('\\bhello\\b','g') |
正则可视化工具
Regulex
可视化图形,对理解正则有非常大的帮助
二话不说先进来这个网站,这个文章将使用这个网站来验证写的例子。
元字符
正则表达式由两种基本字符类组成
- 原义字符
- 元字符
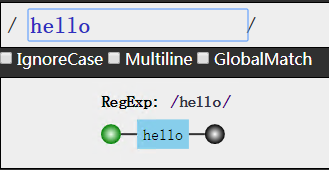
原义字符,就是表示原本意思的字符,像上面正则中的hello,就代表匹配hello这个字符串
元字符呢,就是表示不是原本意思的字符,这样想就简单多了吧。像上面这个\b
既然元字符表示的不是本身的字符,那我如果就要匹配它原本的字符呢?比如说我就要匹配+号,*号,那么请使用 \ 来转义字符
下面这些元字符先随便过一遍先,不用背熟也可往下看~
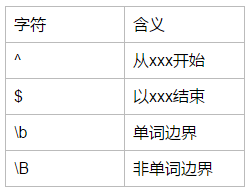
- $ 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘n’ 或 ‘r’。要匹配 $ 字符本身,请使用 $。
- () 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。
- * 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。
- + 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。
- . 匹配除换行符 n 之外的任何单字符。要匹配 . ,请使用 . 。
- [] 标记一个中括号表达式的开始。要匹配 [,请使用 [。
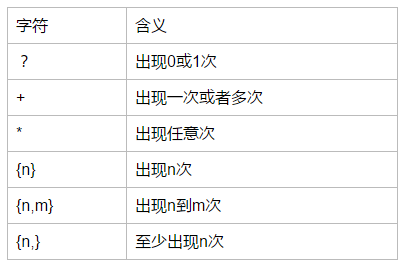
- {} 标记限定符表达式的开始。要匹配 {,请使用 {。
- | 指明两项之间的一个选择。要匹配 |,请使用 |。
- ? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。
- \ 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’n’ 匹配换行符。序列 ‘' 匹配 “”,而 ‘(‘ 则匹配 “(“。
- ^ 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配 ^ 字符本身,请使用 ^。
- \cX 匹配由x指明的控制字符。例如, cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。
- \f 匹配一个换页符。等价于 x0c 和 cL。
- \n 匹配一个换行符。等价于 x0a 和 cJ。
- \r 匹配一个回车符。等价于 x0d 和 cM。
- \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ fnrtv]。注意 Unicode 正则表达式会匹配全角空格符。
- \S 匹配任何非空白字符。等价于 1。
- \t 匹配一个制表符。等价于 x09 和 cI。
- \v 匹配一个垂直制表符。等价于 x0b 和 cK
边界
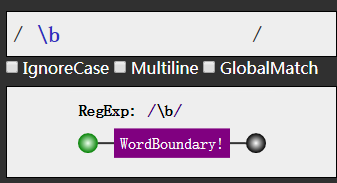
从一开始的例子我们就知道了这个b,不对,是这个\b
他表示的就是单词边界的意思.
我们知道,fck这个是有很多用法的,可以单独用,也可以加个ing多种词性使用。
然后我们只想找到单独的fck,看代码
1 | //作为光荣的社会主义接班人怎么可能用f*ck做例子呢? |
1 | var reg = /is/g; |
两者区别清晰可见,不容我多说了吧,各位客官。
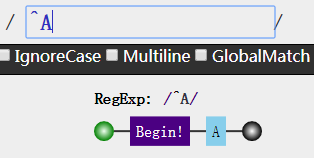
再来看看一个问题,如果我只要开头部分的A字符而文本中间的A字符却不要,又该如何?
只需如此,便可对敌
1 | var reg = /^A/g; |
需要以A为结尾的正则,则是如下
1 | var reg = /A$/g; |
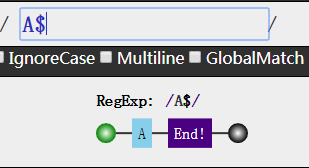
注意,正如开头结尾的位置一样,^和$的位置也是如此,^放在正则表达式前面,$放在表达式后面
字符类
一般情况下,正则表达式一个字符对应字符串的一个字符
比如表达式 \bhello 就表示 匹配 字符\b h e l l o,
如果我们想要匹配一类字符的时候?
比如我要匹配a或者b或者c,我们就可以使用元字符 []来构建一个简单的类
[a,b,c]就把a,b,c归为一类,表示可以匹配a或者b或者c。
如果你会一丢丢英文的话,你应该就可以看懂下面的图,one of a,b,c,也就是匹配abc中任意一个~
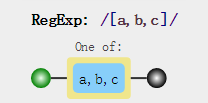
范围类
当我们学习了上面的内容以后,如果我们要写匹配0到9的数字,就应该是这样写
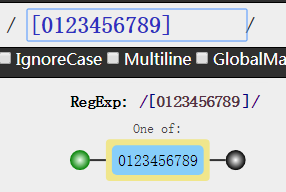
但是如果我要匹配更多呢?那不是键盘都要敲烂了?这正则也太不智能了吧???
显然,你能想到的,创造正则的人也想到了
我们可以这样子
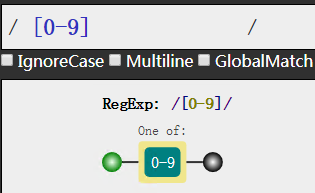
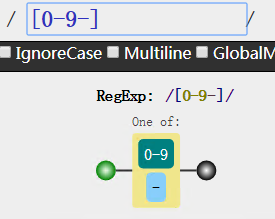
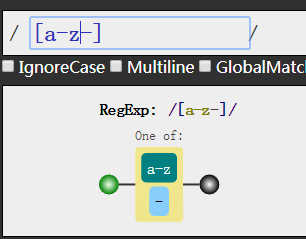
好了,方便了一些,然后你可能又会吃惊,那么我的短横线-呢?我如果要匹配0-9以及短横线呢?
莫慌,只要在后面补回去即可
这个图可以清楚看到有两条分支,也就是说我可以走0-9这条路也可以走短横线这条路
预定义类
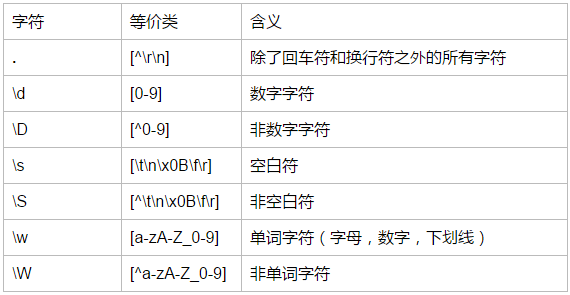
学习了上面以后,我们就可以书写匹配数字的正则了,[0-9]
那么有没有更简便更短的方法呢?
巧了,正则就是辣么强大
在上面的元字符部分内容中,你可能已经窥得其中精妙了
上表格,不是,上图(这个segmentfault哪里插入表格啊??)
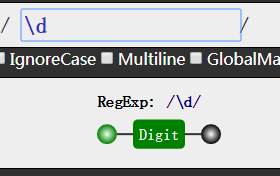
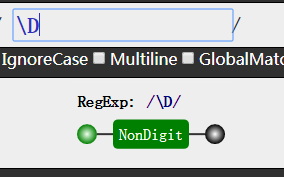
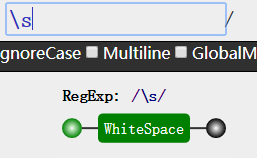
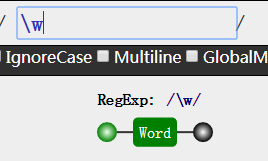
我们可以根据英文单词的意思,来记住这些预定义类的用法。
我们发现,大写字母和小写字母的区别就是取反!,如d和D
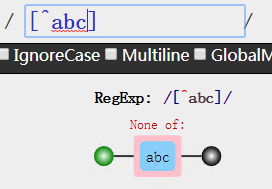
同时我们从表格中的等价类可以发现如果我们要一个类的取反,那么就在类中加一个 ^
none of abc
量词
如果要你写一个匹配10个数字的正则?你会怎么写
诶~你可能已经胸有成竹的写下了
1 | \d\d\d\d\d\d\d\d\d\d |
吃惊,你会发现,尽管是你单身二十余年的右手,依然感到了一丝乏力!
疲惫,有时是在过度劳累之后
为了挽救一些人的右臂,正则有了量词
实现上面的需求我们只要 \d{10}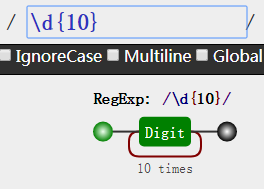
Digit 10times
为了方便一些英语不好的人,比如我,我甚至使用了鲜为人知的百度翻译(广告费私我)
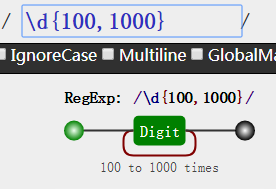
但是,如果我不知道要匹配具体多少个数字呢?反正就是匹配100个到1000个之间的数字
当当当当~
让我们看看可视化工具的结果,方便理解
注意,这个{n,m}是包括n次和m次的哦,是闭区间哦
贪婪模式与非贪婪模式
从上面一则我们知道,如果我们要匹配100到1000个数字的话,是这样写
\d{100,1000}
如果我给的字符串里有1000个数字,但是我只想匹配前面100个呢?
如果按照上面这样写,则如下
1 | var reg = /\d{3,6}/; |
我们可以看到,上面这个例子是匹配了6个数字,将6个数字替换了,尽管他的正则匹配的是3到6个数字。
没错,它是贪婪的!它会尽可能地匹配更多!
这就是正则的 贪婪匹配,这是默认的,如果我们不想要那么贪婪,如何变得容易满足一点?
只需要在量词后面加上 ? 即可
1 | var reg = /\d{3,6}?/; |
可以清楚看到正则只匹配了前面3个数字~这就是正则的非贪婪模式
分支条件
如果我只需要匹配100个或者1000个数字呢?
就只有100和1000两种可能,而不是100到1000任意一个数字,又该如何对敌?
这就要设计到正则的分支条件了
1 | \d{100}|\d{1000} |
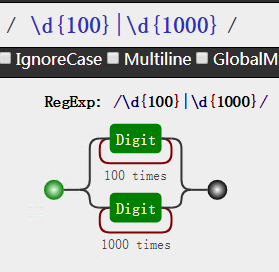
需要注意的是这个 | 分割的是左右两边所有部分,而不是仅仅连着这个符号的左右两部分,看下图
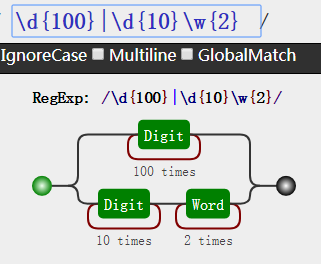
有时候我们只需要一部分是分支,后面走的是同一条主干,只需要把分支用()包含即可
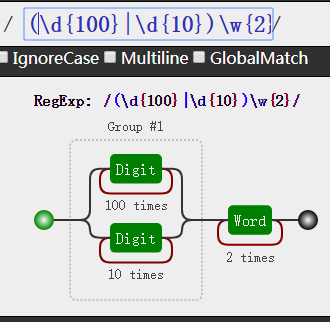
注意:这个匹配是从正则左边的分支条件开始的,如果左边满足了,那么右边就不会在对比!
1 | var reg = /\d{4}|\d{2}/ |
1 | var reg = /\d{2}|\d{4}/ |
前瞻/后顾
sometimes,我们要找寻的字符可能还要依靠前后字符来确定
比如说我要替换连续的2个数字,而且它的前面要连着是2个英文字母,这样的数字我才要
你可能会疑惑,这样写不就完事了吗?
1 | \d{2}\w{2} |
上面匹配的是2个数字和2个字母,虽然是连着的,但是匹配了是4个字符,如果我要替换匹配文本的话,那就替换了4个字符,而我们只想替换2个数字!
这个时候就需要用到断言了
首先我们需要明白几个点
- 正则表达式从文本头部到尾部开始解析,文本尾部方向叫做‘前’,也就是往前走,就是往尾巴走
- 前瞻就是正则表达式匹配到规则(此例中的‘2个数字’)的时候,向前看看,看看是否符合断言(此例中的‘前面连着2个字母’),后瞻/后顾的规则则相反。(javascript不支持后顾)
上表格!
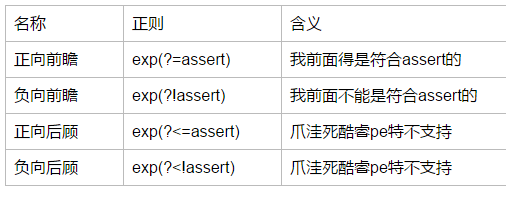
根据表格内容,我们就可以解决这个问题了,注意\w包括数字哦~题目要求是连着2个字母
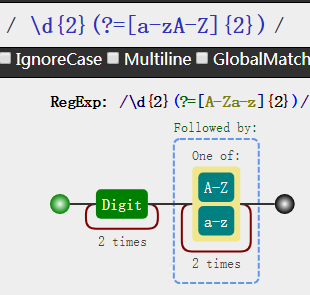
1 | var reg = /\d{2}(?=[a-zA-Z]{2})/; |
只替换了数字,没有替换后面的断言哦!
顺便把这个负向前瞻看看吧
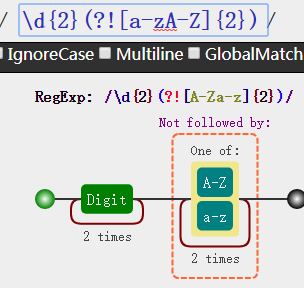
看到这个not followed by 我想你应该知晓用法了
分组
当我们要匹配一个出现三次的单词而不是数字的时候,会怎么写呢?
你可能会这样写
1 | hello{3} |
然后你打开可视化工具
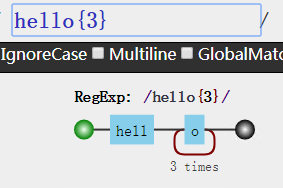
妈耶,居然只重复了我的o字母!死渣则,好过分
其实,我们只要使用()就可以达到分组的目的,使量词作用于分组,上面分支条件中的括号亦是如此
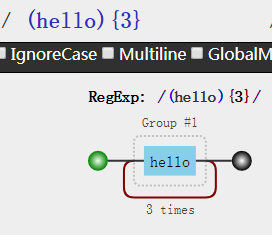
分组以后怎么使用分组内容呢?
首先看一个问题,如何匹配8个不连续的数字?
如果你不使用分组,你会发现根本无从下手,因为你不能判断出有无重复!
我们先公布答案,再来分析一波
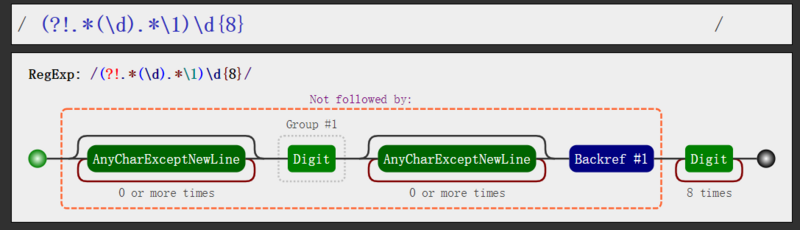
- 首先,这个(?!负向前瞻断言A)表达式B,这里使用的是负向前瞻,也就是说断言A前面的内容(表达式B),不能符合表达式A,这个说法很拗口,我嘴巴都拗不过来了。能听明白吧,这个设计就是,我这个断言是“出现重复的数字”,然后表达式是“8个数字”,”8个数字“不能复合“出现重复的数字”
- 然后,这个 .(\d). 呢,是先找到一个在任意位置出现的数字,为什么是任意位置呢?因为我们判断的重复可能出现在任何位置;看上面的可视化也就可以明白,\d前后有0-n个字符,所以说他是任意位置的。
- 最关键的来了,这个\1代表什么呢?仔细看你可以发现,\d加了一个括号,这个括号就代表着分组,那么是几号分组呢?第一个括号就是分组1(默认情况下),如果还有第二个括号,那就是分组2,前瞻的括号是不算的噢,而这个\1呢就代表着引用这个分组1,使用\2引用分组2。你也许会好奇,我引用它是相当于在这个位置写了一个\d吗?NOP,不仅仅这么简单,它引用的是这个\d的内容,也就是说他会和\d是一样的值!这不就是重复了吗?!!!这个 .(\d).\1 就代表着**任意位置出现了任意次数的重复
- 最后,我们把这些整合在一起就是,匹配8个数字不能出现任意的重复。(?!出现任意重复)8个数字,因为这个(?!)是负向前瞻,所以。。。emmm。。这样就理解了吧。
分组还有其他更详细的内容,但是篇幅有限,马上就到30分钟了。只好捡一些有价值常用的讲了~
嘿嘿嘿
正则就介绍到这里啦~